使用ONNX Runtime加速LLaMA-2推理
作者:Kunal Vaishnavi 和 Parinita Rahi
2023年11月14日 (2023年11月22日更新)
想更快地运行Llama2吗?让我们探索ONNX Runtime如何推动您的Llama2变体,实现更快的推理!
得益于ONNX Runtime的尖端融合和内核优化,现在您可以体验到显著的推理性能提升——对于7B、13B和70B模型,速度提升高达3.8倍。本博客详细介绍了性能增强、深入探讨了ONNX Runtime的融合优化、多GPU推理支持,并指导您如何利用ONNX Runtime的跨平台能力,在不同平台上实现无缝推理。这是一系列即将发布的博客中的第一篇,后续博客将涵盖ONNX Runtime量化更新带来的高效内存使用以及跨平台使用场景的更多方面。
背景:Llama2与微软
Llama2是Meta公司推出的最先进的开源LLM,规模从7B到70B参数不等(7B、13B、70B)。微软和Meta于2023年7月宣布了他们在Azure和Windows上的人工智能合作。作为该公告的一部分,Llama2被添加到Azure AI模型目录中,该目录是基础模型的中心,使开发人员和机器学习(ML)专业人员能够轻松发现、评估、自定义和大规模部署预构建的大型AI模型。
ONNX Runtime允许用户轻松地将这种生成式AI模型的能力集成到您的应用程序和服务中,并通过优化的改进,实现更快的推理速度并降低成本。
利用新的ONNX Runtime优化实现更快的推理
作为新发布的1.16.2版本的一部分,ONNX Runtime现在为Llama2提供了多项内置优化,包括图融合和内核优化。与PyTorch编译模式下CUDA FP16的提示延迟相比,Llama2的Hugging Face (HF) 变体的推理加速情况如下所述。下面显示端到端吞吐量或实际运行吞吐量的定义为:批大小 * (提示长度 + 令牌生成长度) / 实际运行延迟,其中实际运行延迟 = 端到端运行的延迟,令牌生成长度 = 256个生成的令牌。与PyTorch编译模式相比,端到端吞吐量在13B模型上增加了2.4倍,在7B模型上增加了1.8倍。对于更高批大小和序列长度的组合,例如(16, 2048),PyTorch的 eager 模式会超时,而ORT则显示出优于编译模式的性能。
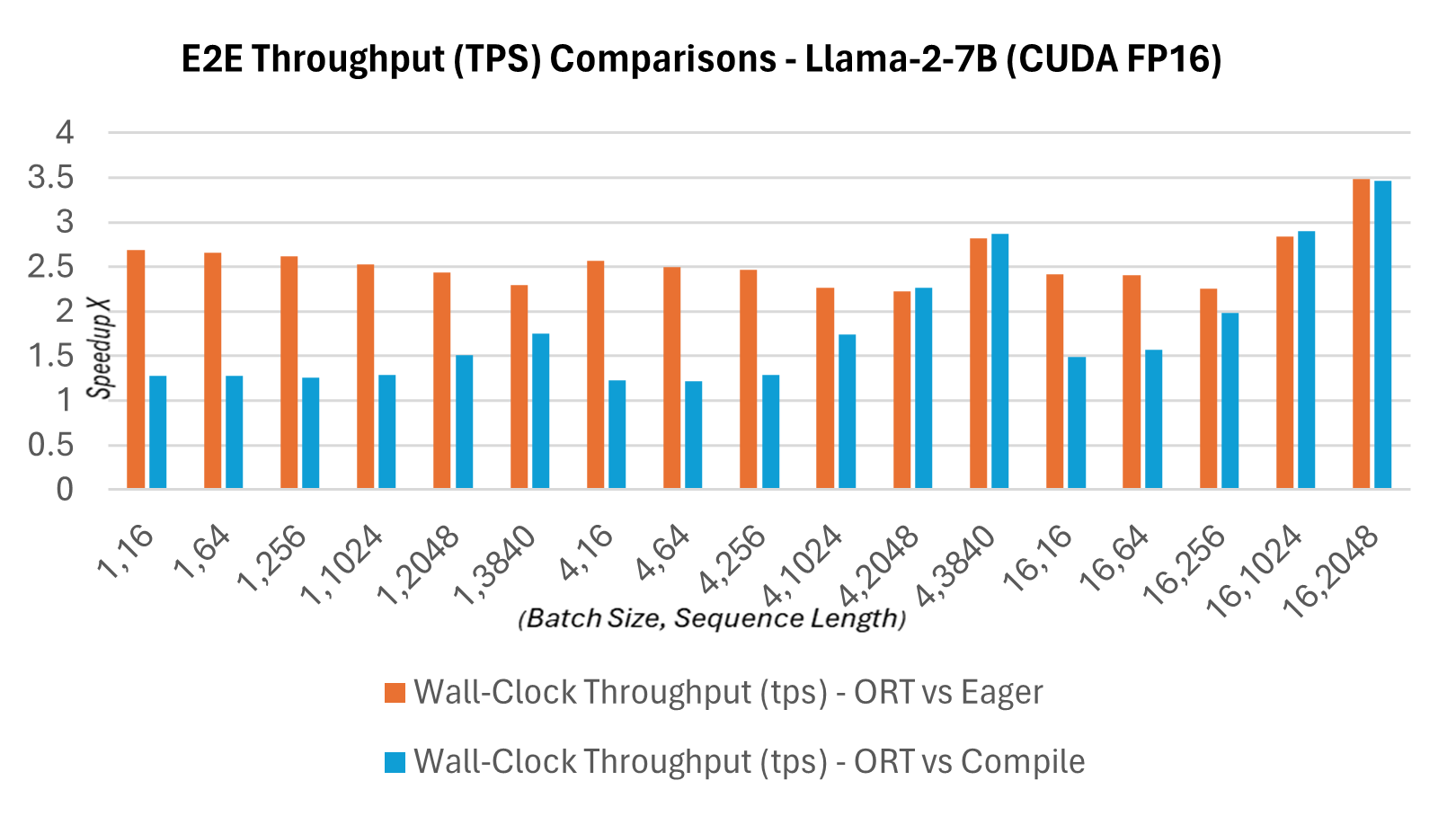
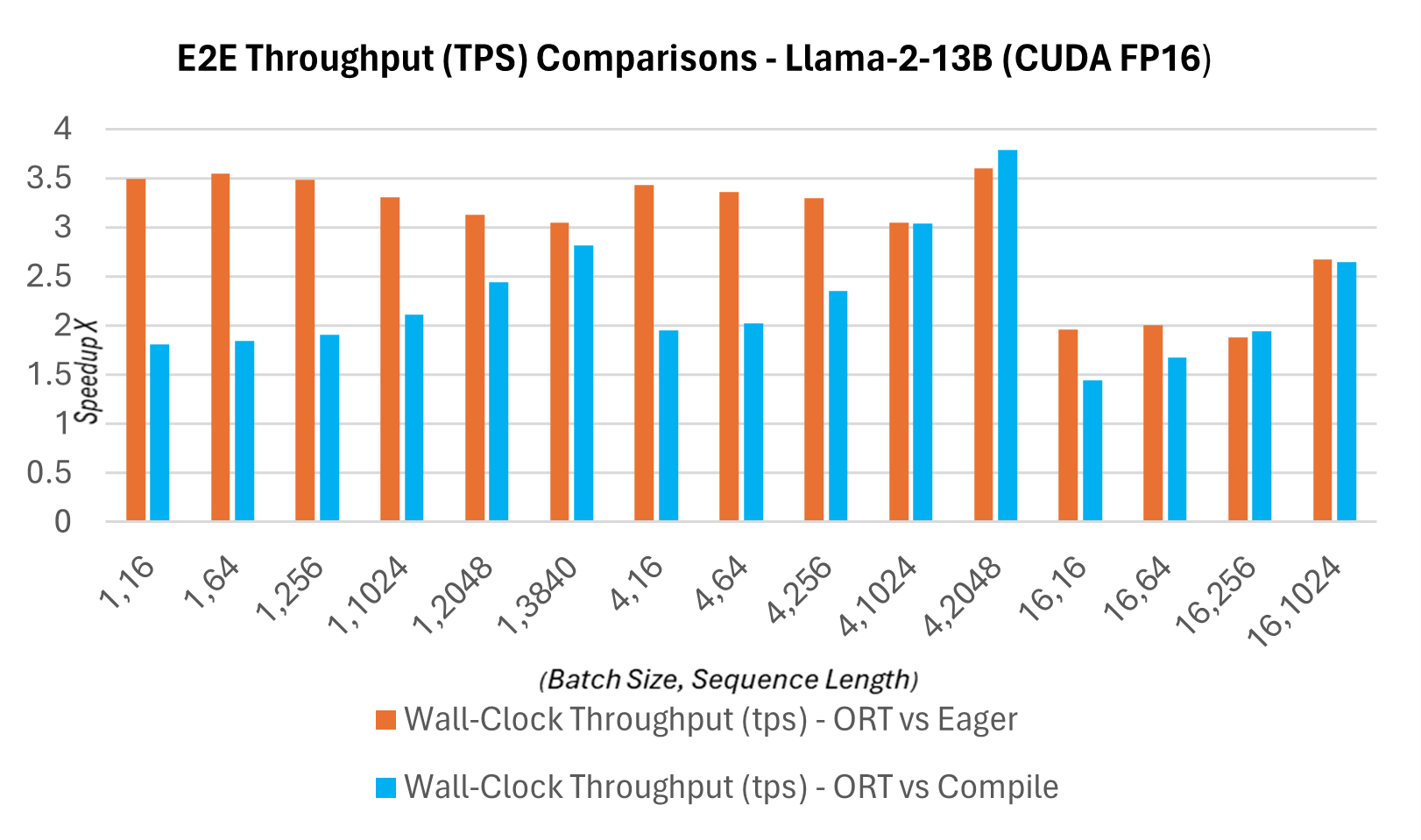
延迟与吞吐量
下图显示了ONNX Runtime与PyTorch版本的Llama2 7B模型在CUDA FP16上的延迟对比。这里的延迟定义为模型完成一次前向传播,生成logits并同步输出所需的时间。
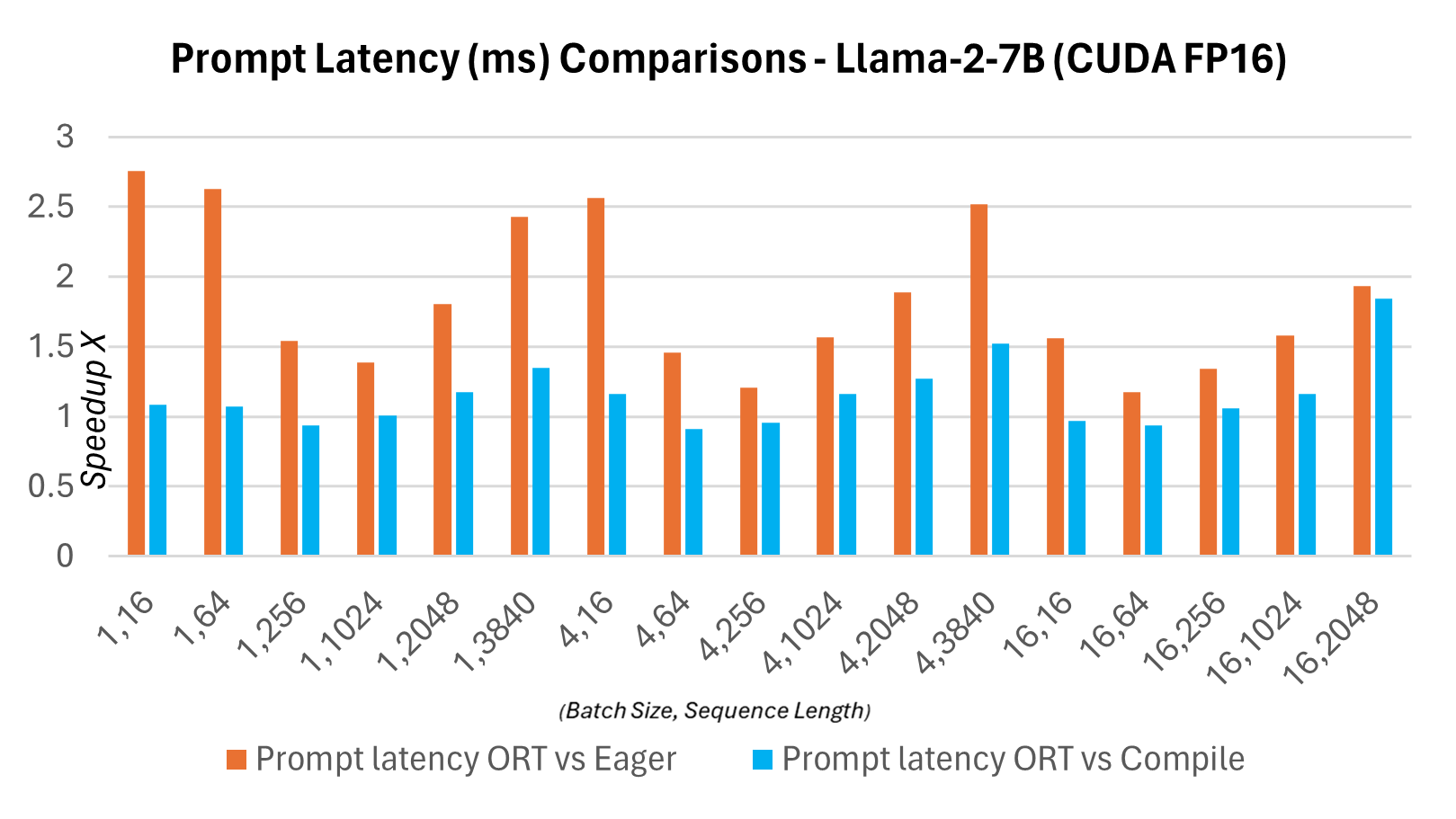
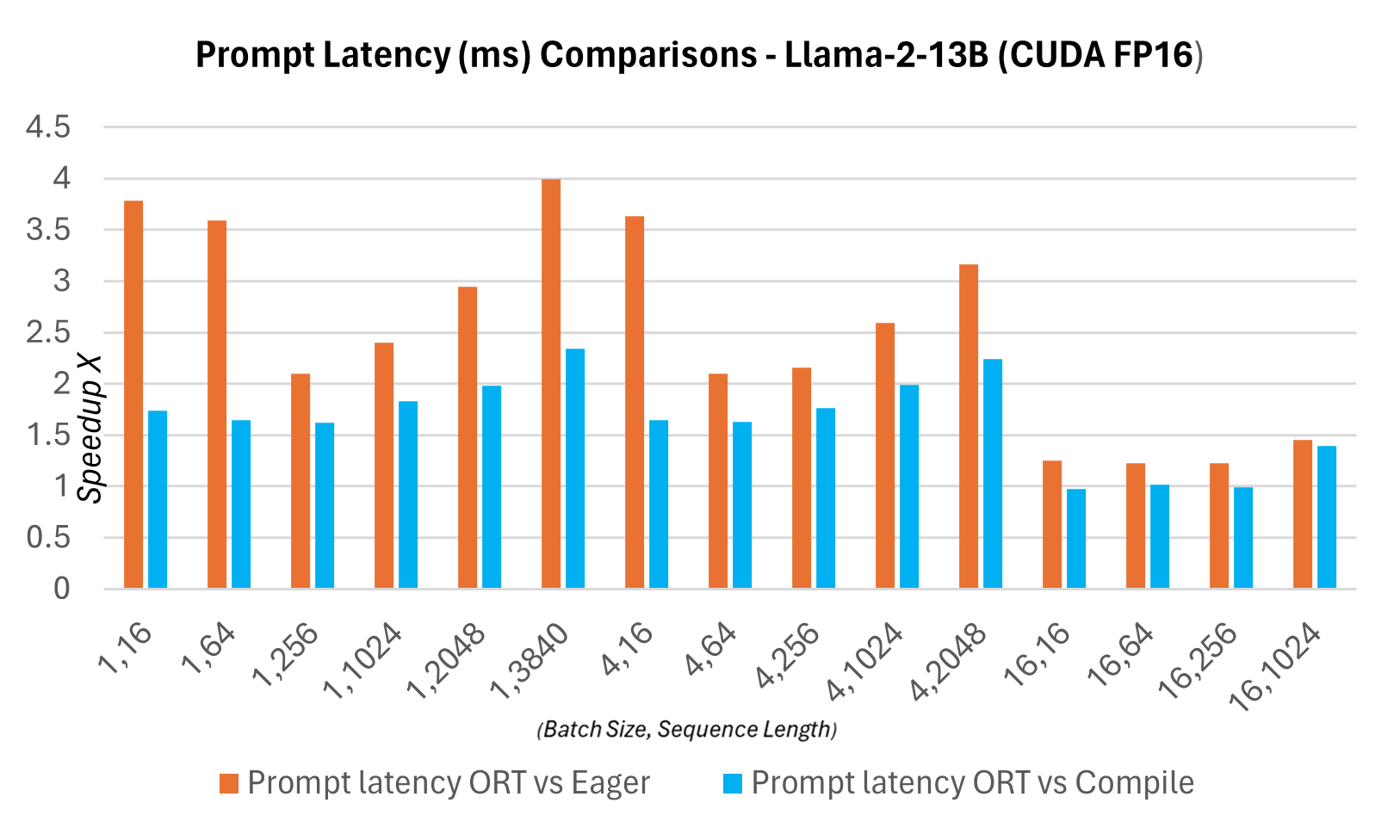
下面的令牌生成吞吐量是前256个生成令牌的平均吞吐量。与PyTorch编译模式相比,令牌生成吞吐量在7B模型上最高提升约1.3倍,在13B模型上最高提升约1.5倍。
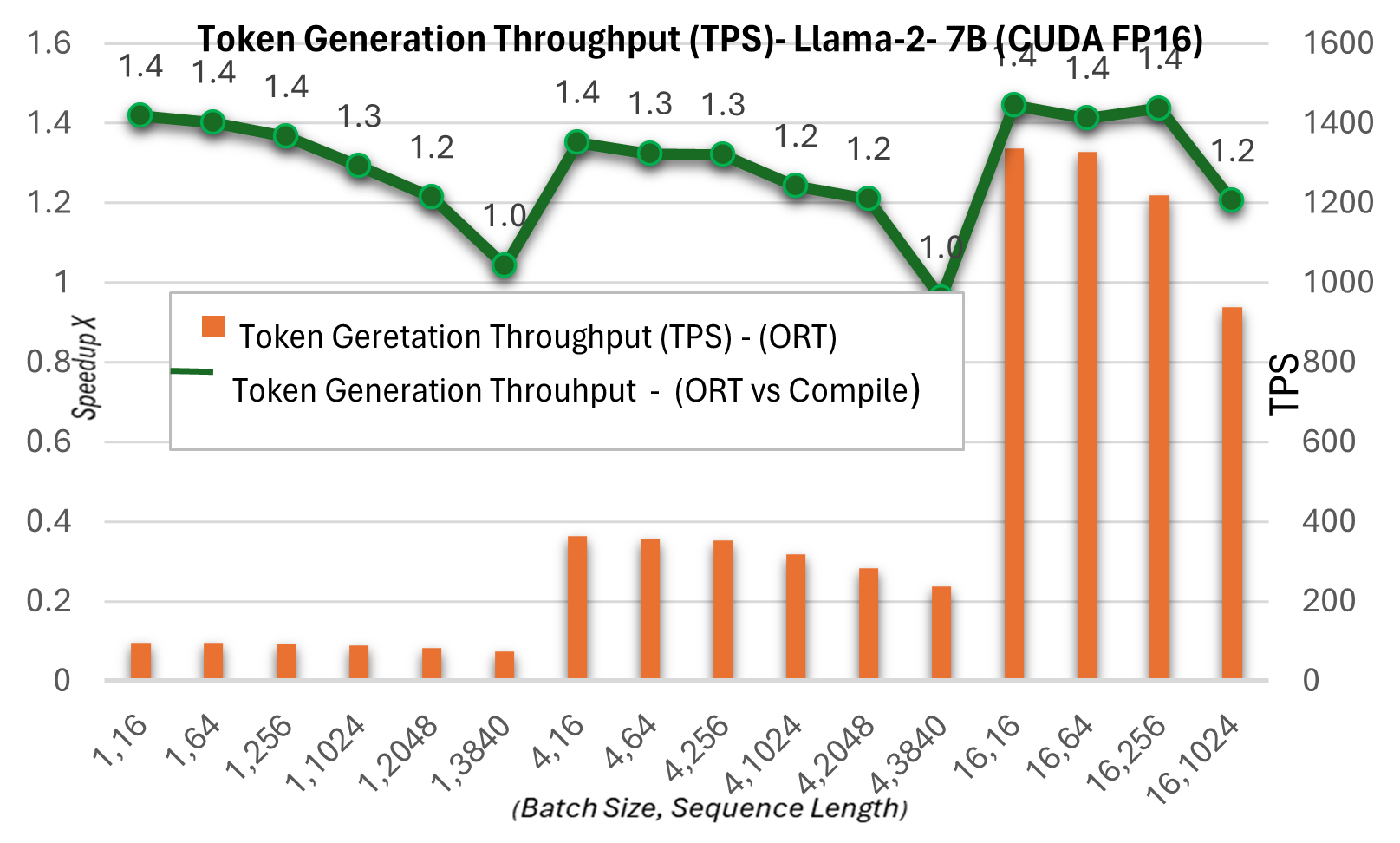
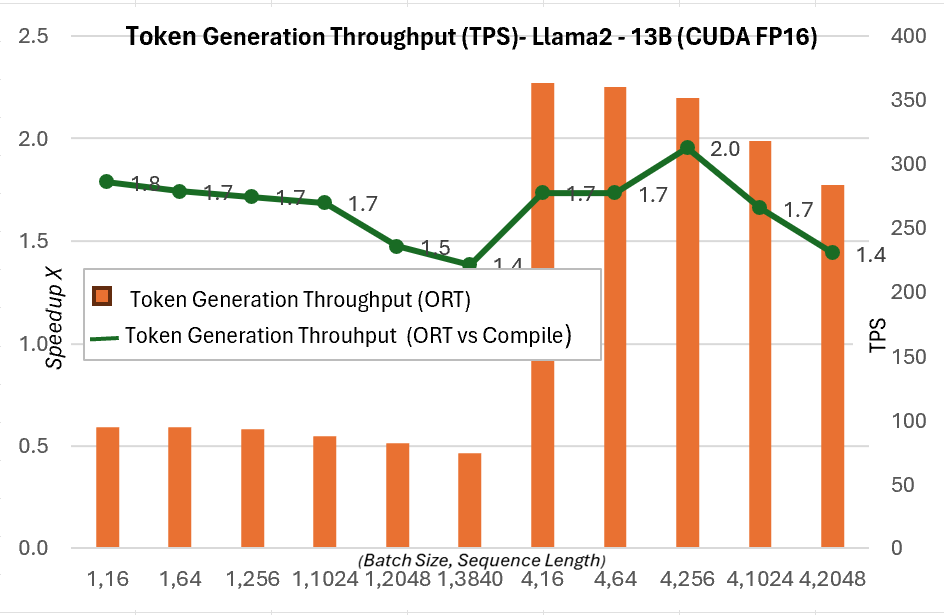
有关这些指标的更多详细信息,请参见此处。
ONNX Runtime与多GPU推理
ONNX Runtime支持多GPU推理,以支持大型模型的部署。即使在FP16精度下,LLaMA-2 70B模型也需要140GB内存。即使配备强大的NVIDIA A100 80GB GPU,加载模型也需要多个GPU进行推理。
ONNX Runtime在70B模型上应用了Megatron-LM张量并行,以将原始模型权重分割到不同的GPU上。对70B模型进行的Megatron分片将FP16精度的PyTorch模型分片为4个分区,将每个分区转换为ONNX格式,然后对转换后的ONNX模型应用新的ONNX Runtime图融合。通过这些优化,70B模型在批大小为1时,令牌生成吞吐量约为每秒30个令牌,对于较短序列长度的端到端吞吐量也从30 tps开始。您可以在此处找到更多示例脚本。
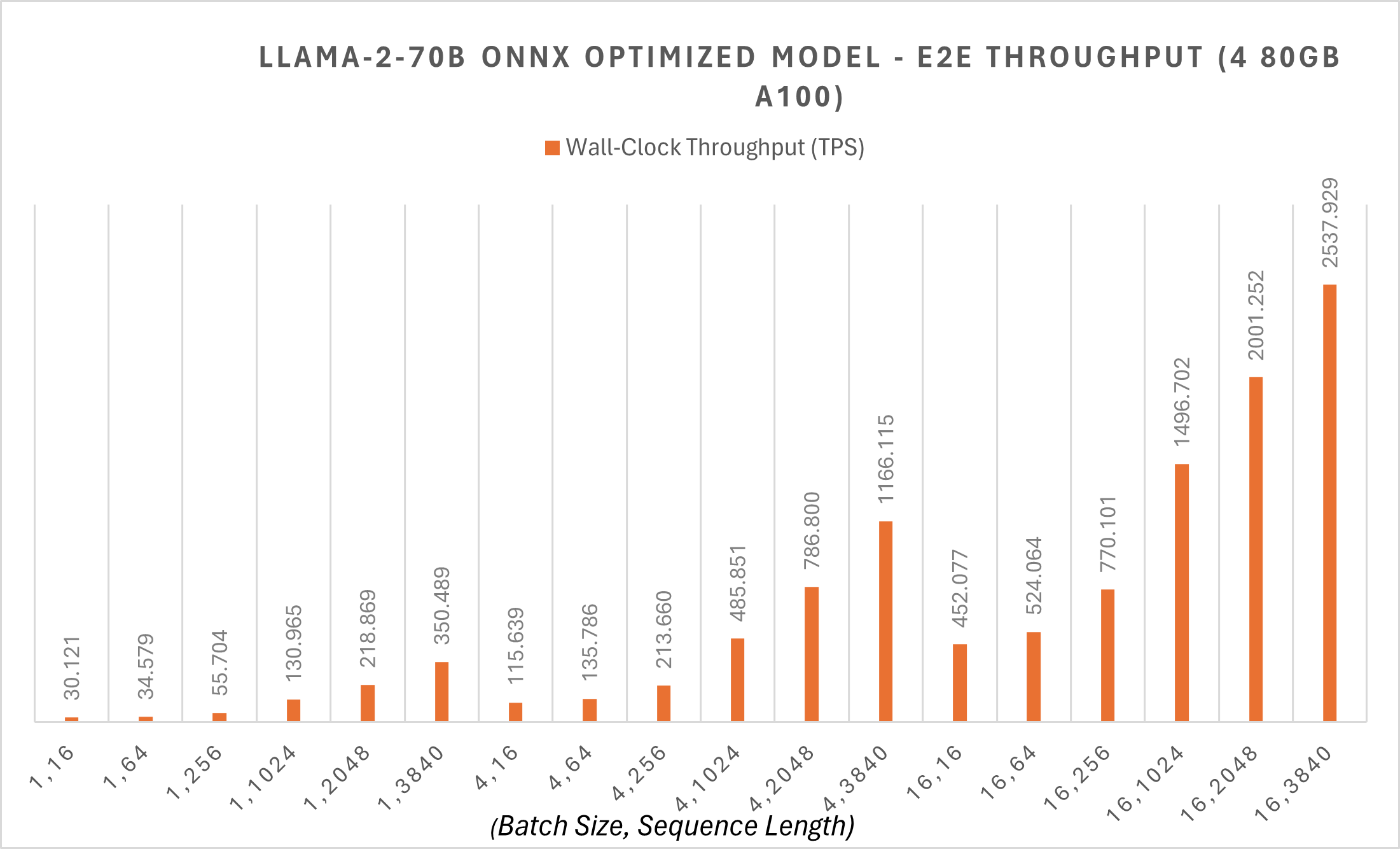
ONNX Runtime优化

ONNX Runtime用于优化的技术,如图融合,适用于最先进的模型。随着这些模型变得更加复杂,应用图融合的技术也会相应调整以适应额外的复杂性。例如,ONNX Runtime现在支持自动化模式匹配,而不是手动匹配图中的融合模式。与其手动检测大型子图并匹配它们形成的众多路径,不如将大型模块导出为函数,然后针对函数的规范进行模式匹配,从而识别融合机会。

举一个具体的例子,图6是构成旋转位置编码计算的节点示例。针对此子图进行模式匹配很麻烦,因为需要验证的路径数量很多。通过将其导出为函数,图的父视图将只显示输入和输出,并将所有这些节点表示为一个单一的运算符。
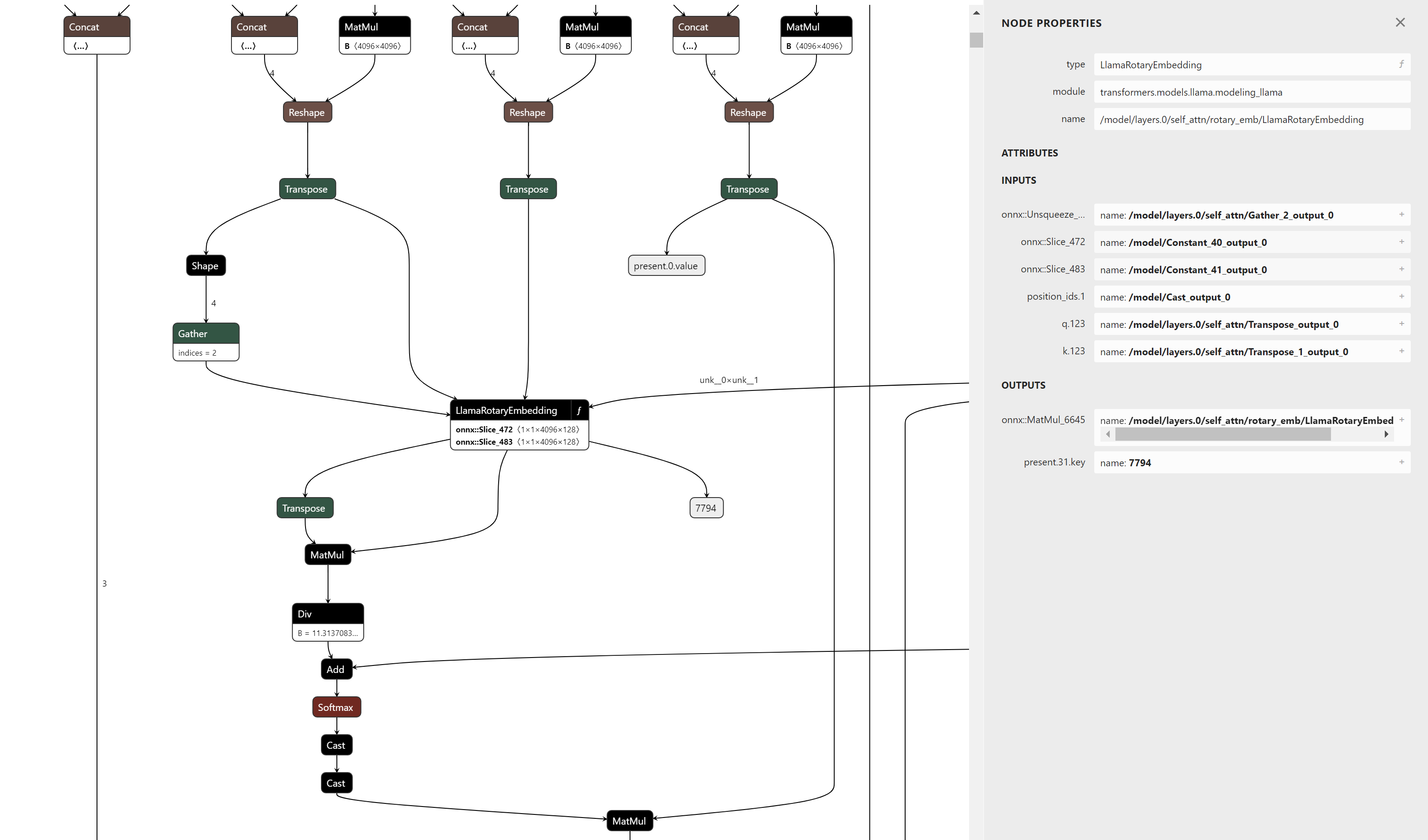
这种方法使得维护和支持未来版本的旋转位置编码计算变得更加容易,因为模式匹配仅取决于运算符的输入和输出,而不是其内部语义表示。它还允许在GPT-NeoX、Falcon、Mistral、Zephyr等类似模型中现有旋转位置编码的实现进行模式匹配和融合,几乎无需更改。
ONNX Runtime还增加了对GroupQueryAttention (GQA) 运算符的支持,该运算符利用新的Flash Attention V2算法及其优化内核来高效计算注意力。GQA运算符支持过去键/值缓存(past KV cache)和当前键/值缓存(present KV cache)之间的过去-当前缓冲区共享。通过将当前KV缓存绑定到过去KV缓存,无需为两个缓存单独分配设备内存。相反,过去KV缓存可以预先分配足够的设备内存,以便在推理过程中无需请求新的设备内存。这减少了在计算密集型工作负载期间KV缓存变大时的内存使用,并通过消除设备内存分配请求来降低延迟。过去-当前缓冲区共享可以启用或禁用,而无需更改ONNX模型,这为最终用户提供了更大的灵活性,让他们决定哪种方法最适合自己。
除了这些融合和内核优化之外,ONNX Runtime还减少了模型的内存使用。除了量化改进(将在未来的文章中介绍)之外,ONNX Runtime将每个旋转位置编码中使用的余弦和正弦缓存的大小压缩了50%。ONNX Runtime中运行旋转位置编码计算的计算内核可以识别这种格式,并使用其并行实现更高效地计算旋转位置编码,同时减少内存使用。旋转位置编码计算内核还支持交错和非交错格式,以分别支持Microsoft版本的LLaMA-2和Hugging Face版本的LLaMA-2,同时共享相同的计算。
这些优化适用于Hugging Face版本(以-hf结尾的模型)和微软版本。您可以从微软的LLaMA-2 ONNX仓库下载优化后的HF版本。敬请期待即将推出的新版微软版本!
使用Olive优化您的模型
Olive是一款硬件感知模型优化工具,它集成了模型压缩、优化和编译等先进技术。我们已通过Olive提供ONNX Runtime优化,让您能够以简单的体验为特定硬件简化整个优化过程。
这是一个使用Olive进行Llama2优化的示例,它利用了本博客中强调的ONNX Runtime优化。不同的优化流程可满足各种需求。例如,您可以根据自己的精度容忍度,灵活选择CPU和GPU推理中量化的不同数据类型。此外,您还可以在客户端GPU上使用Olive-QLoRa微调自己的Llama2模型,并利用ONNX Runtime优化进行推理。
使用示例
这是一个示例notebook,它向您展示了如何在您的应用程序中端到端地使用上述ONNX Runtime优化。
结论
本博客中讨论的进步使得Llama2能够通过ONNX Runtime实现更快的推理,为AI应用和研究提供了激动人心的可能性。随着性能和效率的提升,创新前景广阔,我们热切期待其充满活力的开发者社区能够利用Llama2和ONNX Runtime构建新的应用。敬请关注更多更新!