通过全新的 Olive CLI 普及 AI 模型优化
作者
Jambay Kinley、Hitesh Shah、Xiaoyu Zhang、Devang Patel、Sam Kemp2024年11月11日
👋 简介
在Build 2023大会上,微软宣布推出 Olive (ONNX Live):一个先进的模型优化工具包,旨在简化 AI 模型为 ONNX Runtime 部署进行优化的过程。如下图所示,Olive 可以接收来自 PyTorch 或 Hugging Face 等框架的模型,并输出针对特定部署目标定制的优化 ONNX 模型。
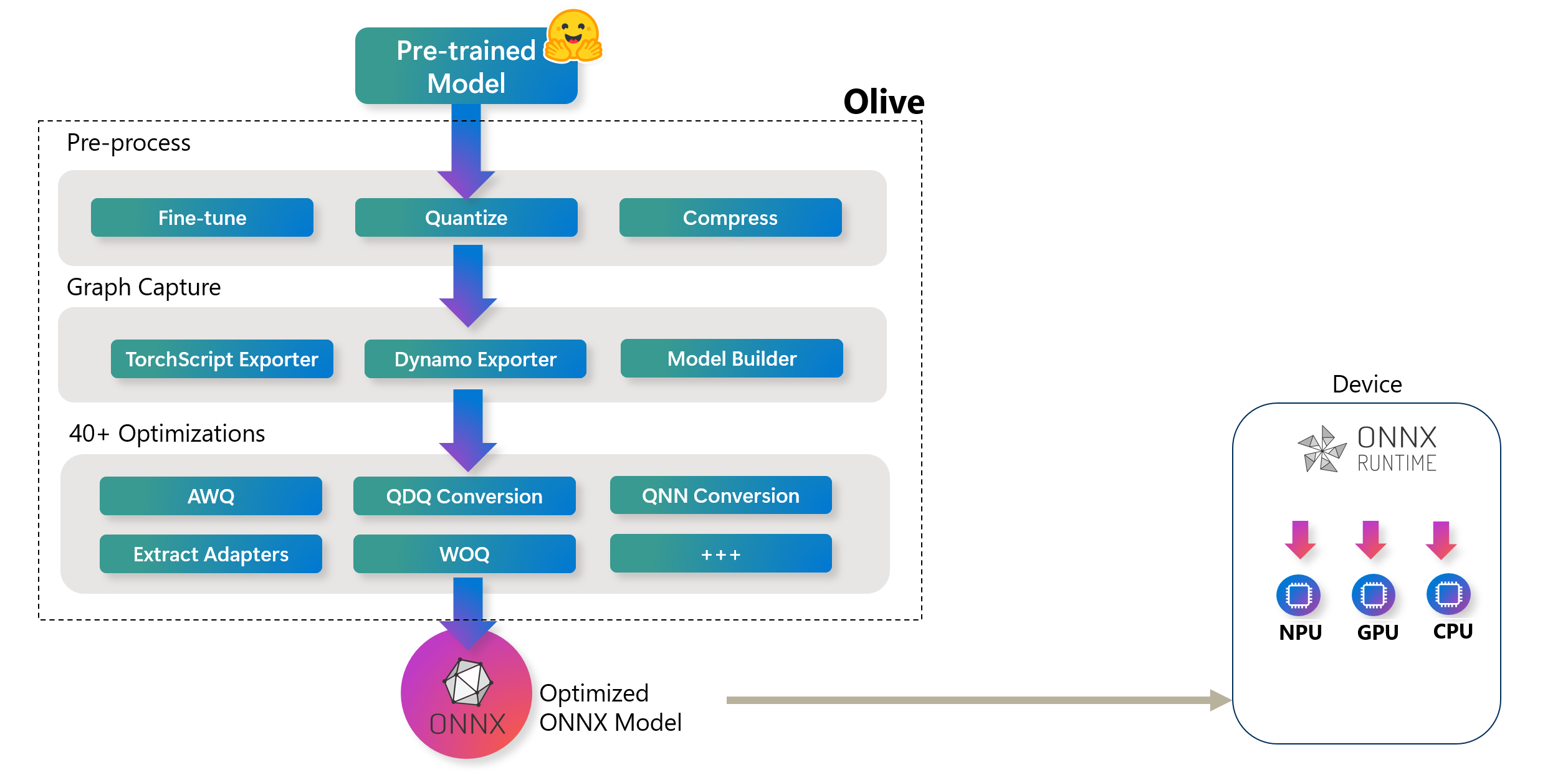 Olive 高级工作流程。这些硬件目标可以包括高通、AMD、英伟达和英特尔等主要硬件供应商提供的各种 AI 加速器(GPU、CPU)
Olive 高级工作流程。这些硬件目标可以包括高通、AMD、英伟达和英特尔等主要硬件供应商提供的各种 AI 加速器(GPU、CPU)Olive 通过一系列称为“通道(passes)”的模型优化任务,以结构化的工作流程运行。这些通道可以包括模型压缩、图捕获、量化和图优化。每个通道都有可调整的参数,可以进行调优以实现准确率和延迟等最佳指标,这些指标由各自的评估器进行评估。该工具利用搜索策略,采用算法自动调优单个通道或通道组,确保部署目标的最佳性能。
虽然 Olive 中使用的工作流程范式非常灵活,但对于刚接触模型优化流程的 AI 开发者来说,学习曲线可能具有挑战性。为了使模型优化更易于上手,我们为常见场景精选了一系列 Olive 工作流程,并将它们以一个简单命令的形式在**适用于 Olive 的全新易用 CLI** 中公开。
 新的 Olive CLI 命令与执行的关联 Olive 工作流程的映射。
新的 Olive CLI 命令与执行的关联 Olive 工作流程的映射。在本博客中,我们将向您展示如何使用 Olive CLI 为 ONNX Runtime 准备模型。
🚀 Olive CLI 入门
首先,使用 pip 安装 Olive
pip install olive-ai[cpu,finetune]🪄 自动优化器
安装 Olive 后,请尝试自动优化器(olive auto-opt)。仅需一个命令,Olive 将会:
- 从 Hugging Face 下载模型
- 将模型结构捕获为 ONNX 图,并将权重转换为 ONNX 格式。
- 优化 ONNX 图(例如,融合)
- 将模型权重量化为 int4
在 CPU 设备上运行 Llama-3.2-1B-Instruct 模型的自动优化器命令是:
olive auto-opt \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path optimized-model \
--device cpu \
--provider CPUExecutionProvider \
--precision int4 \
--use_model_builder True \
--log_level 1
提示:如果您想将目标设置为:
- CUDA GPU,请将
--device更新为gpu,并将--provider更新为CUDAExecutionProvider。- Windows DirectML,请将
--device更新为gpu,并将--provider更新为DmlExecutionProvider。Olive 将应用特定于设备和提供程序的优化。
使用 auto-opt 命令,您可以将输入模型更改为 Hugging Face 上可用的模型(例如,HuggingFaceTB/SmolLM-360M-Instruct),或者位于本地磁盘上的模型。需要注意的是,olive auto-opt 中的 --trust_remote_code 参数仅适用于 Hugging Face 中需要您的机器运行代码的自定义模型——欲了解更多详情,请阅读 Hugging Face 关于 trust_remote_code 的文档。Olive 将自动完成转换(为 ONNX)、优化图和量化权重等过程。
🧪 试验不同的量化算法
Olive CLI 允许您试验许多不同的量化算法——例如 AWQ、GPTQ 和 QuaRot——以及这些算法的不同实现。例如,要使用激活感知量化 (AWQ) 量化 Llama-3.2-1B-Instruct:
注意:您的计算机需要安装 CUDA GPU 设备和相关的驱动程序才能运行 AWQ、GPTQ 和 QuaRot 量化。此外,您应该使用以下命令安装 AutoAWQ 包:
pip install autoawq
olive quantize \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--algorithm awq \
--output_path quantized-model \
--log_level 1
使用 AWQ 方法时,量化命令将输出一个 PyTorch 模型,如果您打算在 ONNX Runtime 上使用该模型,可以使用以下命令将其转换为 ONNX:
olive capture-onnx-graph \
--model_name_or_path quantized-model/model \
--use_ort_genai True \
--log_level 1 \
🎚️ 微调
Olive CLI 还提供了使用 LoRA 或 QLoRA 根据我们自己的数据针对特定任务微调 AI 模型的工具。以下示例将微调 Llama-3.2-1B-Instruct 用于短语分类(给定一个英文短语,它将输出该短语的类别,例如快乐/悲伤/恐惧/惊喜)。
olive finetune \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path models/llama3.2/ft \
--data_name xxyyzzz/phrase_classification \
--text_template "<|start_header_id|>user<|end_header_id|>\n{phrase}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n{tone}" \
--method qlora \
--max_steps 30 \
--log_level 1 \
微调命令将输出一个 Hugging Face PEFT 适配器,您可以使用以下命令为 ONNX Runtime 准备它:
# Step 1 - capture the ONNX graph of the base model and adapter
olive capture-onnx-graph \
--model_name_or_path models/llama3.2/ft/model \
--adapter_path models/llama3.2/ft/adapter \
--use_ort_genai \
--output_path models/llama3.2/onnx \
--log_level 1
# Step 2 - Extract adapter weights from ONNX model and store in separate file for ORT
olive generate-adapter \
--model_name_or_path models/llama3.2/onnx \
--output_path adapter-onnx \
--log_level 1
🤝 使用 ONNX Runtime 的 Generate API 推断您的优化 AI 模型
以下 Python 代码创建了一个简单的基于控制台的聊天界面,用于使用 ONNX Runtime 的 Generate API 推断您的优化模型。
提示:其他语言绑定——例如 C#、C/C++、Java——更多即将推出。有关最新列表,请访问ONNX Runtime 的 Generate API GitHub 页面
import onnxruntime_genai as og
import numpy as np
import os
model_folder = "optimized-model/model"
# Load the base model and tokenizer
model = og.Model(model_folder)
tokenizer = og.Tokenizer(model)
tokenizer_stream = tokenizer.create_stream()
# Set the max length to something sensible by default,
# since otherwise it will be set to the entire context length
search_options = {}
search_options['max_length'] = 200
search_options['past_present_share_buffer'] = False
chat_template = """<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
"""
text = input("Input: ")
# Keep asking for input phrases
while text != "exit":
if not text:
print("Error, input cannot be empty")
exit
# generate prompt (prompt template + input)
prompt = f'{chat_template.format(input=text)}'
# encode the prompt using the tokenizer
input_tokens = tokenizer.encode(prompt)
params = og.GeneratorParams(model)
params.set_search_options(**search_options)
params.input_ids = input_tokens
generator = og.Generator(model, params)
print("Output: ", end='', flush=True)
# stream the output
try:
while not generator.is_done():
generator.compute_logits()
generator.generate_next_token()
new_token = generator.get_next_tokens()[0]
print(tokenizer_stream.decode(new_token), end='', flush=True)
except KeyboardInterrupt:
print(" --control+c pressed, aborting generation--")
print()
text = input("Input: ")结论
在本博客中,我们展示了如何使用新的 Olive CLI 为 ONNX Runtime 构建模型,然后使用 ONNX Runtime 的 Generate API 推断这些模型。Olive CLI 命令会为您执行精选的 Olive 工作流程,这意味着您将继续获得以下所有优势:
- 减少通过试错手动试验不同图优化、压缩和量化技术所带来的挫败感和时间消耗。定义您的质量和性能约束,让 Olive 自动为您找到最佳模型。
- 40多个内置模型优化组件,涵盖量化、压缩、图优化和微调等领域的尖端技术。
- 支持创建模型,使其能够使用Multi LoRA 范式进行服务。
- Hugging Face 和 Azure AI 集成。
- 内置缓存机制,可节省成本并增强团队协作。正如我们之前在一篇博客文章中分享的,Olive 还支持共享缓存。