注意
前往末尾 以下载完整示例代码。
使用ONNX Runtime进行训练、转换和预测#
本示例演示了一个端到端场景,从训练机器学习模型到使用其转换后的形式。
训练逻辑回归模型#
第一步是获取鸢尾花数据集。
然后我们拟合一个模型。
我们计算测试集上的预测并显示混淆矩阵。
[[16 0 0]
[ 0 13 0]
[ 0 0 9]]
转换为ONNX格式#
我们使用模块 sklearn-onnx 将模型转换为ONNX格式。
from skl2onnx import convert_sklearn # noqa: E402
from skl2onnx.common.data_types import FloatTensorType # noqa: E402
initial_type = [("float_input", FloatTensorType([None, 4]))]
onx = convert_sklearn(clr, initial_types=initial_type)
with open("logreg_iris.onnx", "wb") as f:
f.write(onx.SerializeToString())
我们使用ONNX Runtime加载模型,并查看其输入和输出。
import onnxruntime as rt # noqa: E402
sess = rt.InferenceSession("logreg_iris.onnx", providers=rt.get_available_providers())
print(f"input name='{sess.get_inputs()[0].name}' and shape={sess.get_inputs()[0].shape}")
print(f"output name='{sess.get_outputs()[0].name}' and shape={sess.get_outputs()[0].shape}")
input name='float_input' and shape=[None, 4]
output name='output_label' and shape=[None]
我们计算预测结果。
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
import numpy # noqa: E402
pred_onx = sess.run([label_name], {input_name: X_test.astype(numpy.float32)})[0]
print(confusion_matrix(pred, pred_onx))
[[16 0 0]
[ 0 13 0]
[ 0 0 9]]
预测结果完全一致。
概率#
计算ROC曲线等其他相关指标需要概率。我们首先看看如何使用scikit-learn获取它们。
prob_sklearn = clr.predict_proba(X_test)
print(prob_sklearn[:3])
[[9.73807986e-01 2.61918034e-02 2.10231516e-07]
[1.16978689e-04 4.59359347e-02 9.53947087e-01]
[9.69963264e-01 3.00365409e-02 1.95440805e-07]]
然后使用ONNX Runtime。概率显示为
prob_name = sess.get_outputs()[1].name
prob_rt = sess.run([prob_name], {input_name: X_test.astype(numpy.float32)})[0]
import pprint # noqa: E402
pprint.pprint(prob_rt[0:3])
[{0: 0.9738079905509949, 1: 0.02619178779423237, 2: 2.1023127771968575e-07},
{0: 0.00011697870650095865, 1: 0.04593595489859581, 2: 0.9539470672607422},
{0: 0.9699633121490479, 1: 0.03003653697669506, 2: 1.9544067697552236e-07}]
让我们进行基准测试。
from timeit import Timer # noqa: E402
def speed(inst, number=5, repeat=10):
timer = Timer(inst, globals=globals())
raw = numpy.array(timer.repeat(repeat, number=number))
ave = raw.sum() / len(raw) / number
mi, ma = raw.min() / number, raw.max() / number
print(f"Average {ave:1.3g} min={mi:1.3g} max={ma:1.3g}")
return ave
print("Execution time for clr.predict")
speed("clr.predict(X_test)")
print("Execution time for ONNX Runtime")
speed("sess.run([label_name], {input_name: X_test.astype(numpy.float32)})[0]")
Execution time for clr.predict
Average 5.02e-05 min=4.51e-05 max=7.65e-05
Execution time for ONNX Runtime
Average 1.94e-05 min=1.69e-05 max=3.14e-05
1.9424800001388576e-05
让我们对一个类似于网络服务所经历的场景进行基准测试:模型必须一次进行一个预测,而不是批量预测。
def loop(X_test, fct, n=None):
nrow = X_test.shape[0]
if n is None:
n = nrow
for i in range(n):
im = i % nrow
fct(X_test[im : im + 1])
print("Execution time for clr.predict")
speed("loop(X_test, clr.predict, 50)")
def sess_predict(x):
return sess.run([label_name], {input_name: x.astype(numpy.float32)})[0]
print("Execution time for sess_predict")
speed("loop(X_test, sess_predict, 50)")
Execution time for clr.predict
Average 0.00217 min=0.00161 max=0.00384
Execution time for sess_predict
Average 0.000319 min=0.000314 max=0.000343
0.00031904154000130804
让我们对概率进行相同的操作。
print("Execution time for predict_proba")
speed("loop(X_test, clr.predict_proba, 50)")
def sess_predict_proba(x):
return sess.run([prob_name], {input_name: x.astype(numpy.float32)})[0]
print("Execution time for sess_predict_proba")
speed("loop(X_test, sess_predict_proba, 50)")
Execution time for predict_proba
Average 0.00223 min=0.00217 max=0.00228
Execution time for sess_predict_proba
Average 0.000319 min=0.000314 max=0.000344
0.0003189511999983097
第二次比较结果更好,因为在这种体验中,ONNX Runtime在每种情况下都会计算标签和概率。
使用RandomForest进行基准测试#
我们首先训练模型并将其保存为ONNX格式。
from sklearn.ensemble import RandomForestClassifier # noqa: E402
rf = RandomForestClassifier(n_estimators=10)
rf.fit(X_train, y_train)
initial_type = [("float_input", FloatTensorType([1, 4]))]
onx = convert_sklearn(rf, initial_types=initial_type)
with open("rf_iris.onnx", "wb") as f:
f.write(onx.SerializeToString())
我们进行比较。
sess = rt.InferenceSession("rf_iris.onnx", providers=rt.get_available_providers())
def sess_predict_proba_rf(x):
return sess.run([prob_name], {input_name: x.astype(numpy.float32)})[0]
print("Execution time for predict_proba")
speed("loop(X_test, rf.predict_proba, 50)")
print("Execution time for sess_predict_proba")
speed("loop(X_test, sess_predict_proba_rf, 50)")
Execution time for predict_proba
Average 0.0162 min=0.0159 max=0.0175
Execution time for sess_predict_proba
Average 0.000309 min=0.000303 max=0.000338
0.0003093015199999627
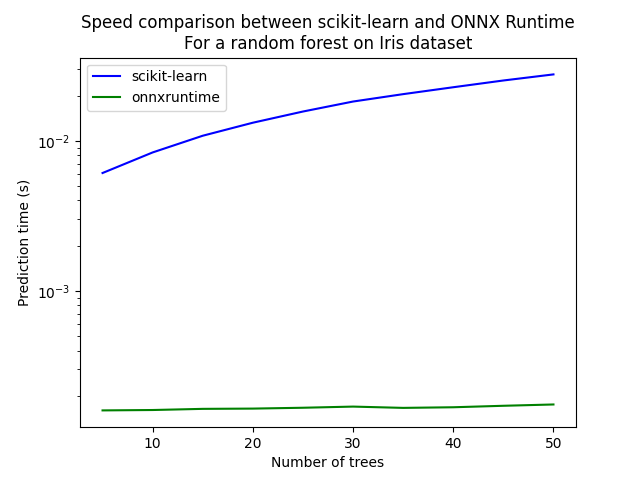
让我们看看不同数量的树的表现。
measures = []
for n_trees in range(5, 51, 5):
print(n_trees)
rf = RandomForestClassifier(n_estimators=n_trees)
rf.fit(X_train, y_train)
initial_type = [("float_input", FloatTensorType([1, 4]))]
onx = convert_sklearn(rf, initial_types=initial_type)
with open(f"rf_iris_{n_trees}.onnx", "wb") as f:
f.write(onx.SerializeToString())
sess = rt.InferenceSession(f"rf_iris_{n_trees}.onnx", providers=rt.get_available_providers())
def sess_predict_proba_loop(x):
return sess.run([prob_name], {input_name: x.astype(numpy.float32)})[0] # noqa: B023
tsk = speed("loop(X_test, rf.predict_proba, 25)", number=5, repeat=4)
trt = speed("loop(X_test, sess_predict_proba_loop, 25)", number=5, repeat=4)
measures.append({"n_trees": n_trees, "sklearn": tsk, "rt": trt})
from pandas import DataFrame # noqa: E402
df = DataFrame(measures)
ax = df.plot(x="n_trees", y="sklearn", label="scikit-learn", c="blue", logy=True)
df.plot(x="n_trees", y="rt", label="onnxruntime", ax=ax, c="green", logy=True)
ax.set_xlabel("Number of trees")
ax.set_ylabel("Prediction time (s)")
ax.set_title("Speed comparison between scikit-learn and ONNX Runtime\nFor a random forest on Iris dataset")
ax.legend()
5
Average 0.0061 min=0.0055 max=0.00783
Average 0.00016 min=0.000153 max=0.000178
10
Average 0.00836 min=0.00798 max=0.00938
Average 0.000161 min=0.000152 max=0.000184
15
Average 0.0108 min=0.0104 max=0.0118
Average 0.000164 min=0.000155 max=0.000191
20
Average 0.0132 min=0.0128 max=0.0142
Average 0.000165 min=0.000155 max=0.00019
25
Average 0.0156 min=0.0153 max=0.0165
Average 0.000167 min=0.000156 max=0.000186
30
Average 0.0182 min=0.0179 max=0.0191
Average 0.00017 min=0.000158 max=0.000193
35
Average 0.0204 min=0.02 max=0.0215
Average 0.000166 min=0.000157 max=0.000189
40
Average 0.0227 min=0.0224 max=0.0236
Average 0.000168 min=0.000159 max=0.00019
45
Average 0.0252 min=0.0248 max=0.0262
Average 0.000172 min=0.000163 max=0.000195
50
Average 0.0276 min=0.0273 max=0.0285
Average 0.000175 min=0.000167 max=0.000199
<matplotlib.legend.Legend object at 0x73024ced4b50>
脚本总运行时间: (0分钟 5.099秒)