用于训练的 ONNX Runtime
ONNX Runtime 可用于加速大型模型训练和设备端训练。
大型模型训练
ORTModule 可加速基于 Transformer 的大型 PyTorch 模型的训练。只需少量代码更改,即可减少训练时间和训练成本。它基于 ONNX Runtime 和 ONNX 格式的高度成功且经过验证的技术构建。它可以与 DeepSpeed 等技术结合使用,并加速最先进 LLM 的预训练和微调。它已集成到 Hugging Face Optimum 库中,该库提供了 ORTTrainer API,可使用 ONNX Runtime 作为训练加速的后端。
- model = build_model() # 用户的 PyTorch 模型
+ model = ORTModule(build_model())开始大型模型训练 →
优势
更快的训练速度
优化的内核和内存优化可将训练时间提速 1.5 倍以上。
灵活且可扩展的硬件支持
相同的模型和 API 可与 NVIDIA 和 AMD GPU 配合使用,并且可扩展的“执行提供程序”架构允许您插入自定义运算符、优化器和硬件加速器。
PyTorch 生态系统的一部分
ONNX Runtime Training 可通过 torch-ort 包获取,作为 Azure Container for PyTorch (ACPT) 的一部分,并与现有的 PyTorch 模型训练管道无缝集成。
支持 Azure AI 精选模型
在 Azure AI | Machine Learning Studio 模型目录中,已为精选模型启用 ORT 训练。
可用于加速 Llama-2-7b 等流行模型
ORT 训练可通过这些脚本加速 Hugging Face 模型,例如 Llama-2-7b。
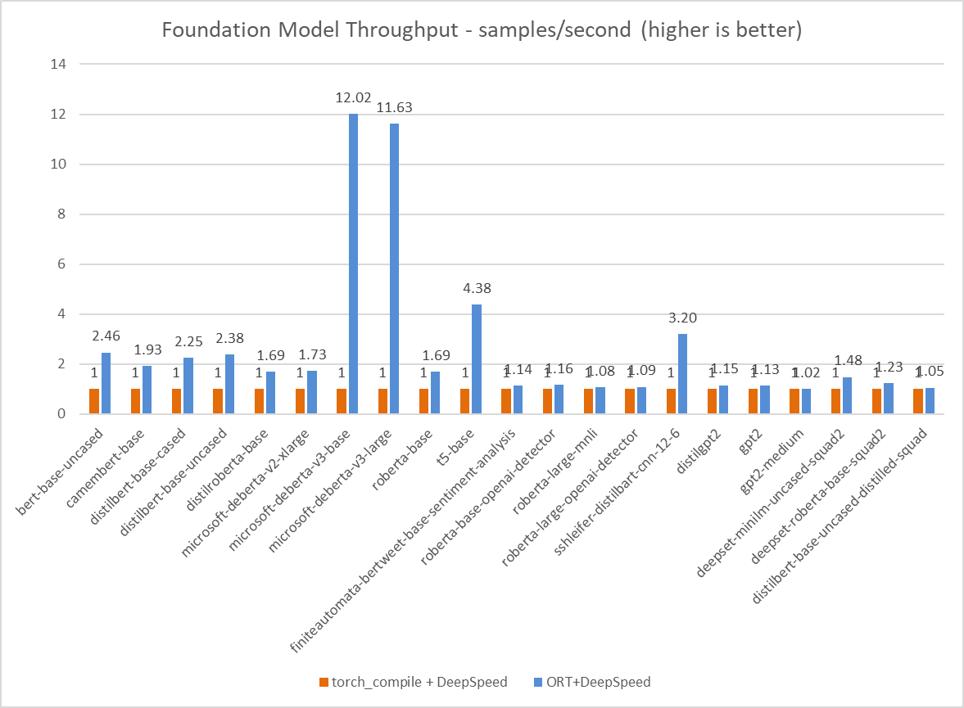
通过 ORT 训练提升基础模型性能
设备端训练
设备端训练是指在边缘设备(例如手机、嵌入式设备、游戏机、网络浏览器等)上训练模型的过程。这与在服务器或云端训练形成对比。设备端训练扩展了推理生态系统,以利用设备上的数据在边缘提供定制化的用户体验。一旦模型在设备上训练完成,它就可以用于获取推理模型进行部署、更新联邦学习的全局权重或创建检查点以供将来使用。它还可以通过在设备上训练来保护用户隐私。
开始设备端训练 →
优势
内存和性能效率
以降低设备上的资源消耗
简单的 API 和多种语言绑定
使其易于在多个平台目标上扩展
提高数据隐私和安全性
尤其是在处理无法与服务器或云共享的敏感数据时
同一解决方案跨平台运行
在云端、桌面、边缘和移动设备上
用例
个性化任务:模型需要在用户数据上进行训练
示例- 图像/音频分类
- 文本预测
联邦学习任务:模型在分布在多个设备上的数据上进行本地训练,以构建更强大的聚合全局模型
示例- 医学研究
- 自动驾驶汽车
- 机器人技术