使用 ONNX Runtime 加速 Phi-2、CodeLlama、Gemma 及其他生成式 AI 模型
作者
Parinita Rahi, Sunghoon Choi, Yufeng Li, Kshama Pawar, Ashwini Khade, Ye Wang2024 年 2 月 26 日
在速度和效率至关重要的快速发展环境中,ONNX Runtime (ORT) 允许用户轻松地将生成式 AI 模型的强大功能集成到其应用程序和服务中,并通过优化的方式,实现更快的推理速度并有效降低成本。这些优化包括最先进的融合和内核优化,有助于提升模型性能。最近发布的 ONNX Runtime 1.17 版本提升了包括 Phi-2、Mistral、CodeLlama、Orca-2 等在内的多个生成式 AI 模型的推理性能。ONNX Runtime 是一个从训练到推理的完整小型语言模型 (SLM) 解决方案,与其他框架相比显示出显著的加速。通过支持 float32、float16 和 int4,ONNX Runtime 的推理增强功能提供了最大的灵活性和性能。
在这篇博客中,我们将介绍针对 Phi-2、Mistral、CodeLlama、SD-Turbo、SDXL-Turbo、Llama2 和 Orca-2 等最新生成式 AI 模型在训练和推理方面的显著优化加速。对于这些模型架构,与 PyTorch 和 Llama.cpp 等其他框架相比,ONNX Runtime 在各种批处理大小和提示长度下都显著提高了性能。这些使用 ONNX Runtime 的优化现在也可以通过 Olive 获得。
快速链接
Phi-2
Phi-2 是一个由微软开发的拥有 27 亿参数的 Transformer 模型。它是一个小型语言模型 (SLM),展现出卓越的推理和语言理解能力。Phi-2 体积小巧,是研究人员探索机械可解释性、安全性改进以及针对不同任务进行微调实验等各个方面的绝佳平台。
ONNX Runtime 1.17 引入了支持 Phi-2 模型的内核更改,包括针对 Phi-2 的 Attention、Multi-Head Attention、Grouped-Query Attention 和 RotaryEmbedding 的优化。具体而言,已添加对以下功能的支持:
- Multi-Head Attention CPU 内核中的因果掩码
- Attention 和 Rotary Embedding 内核中的 rotary_embedding_dim
- Grouped-Query Attention 内核中的 bfloat16
支持基于 TorchDynamo 的 Phi-2 ONNX 导出,并且优化脚本在此基础上构建。
对于 Phi-2 推理,使用 float16 和 int4 量化的 ORT 在所有提示长度下都比使用 float32 的 ORT、PyTorch 和 Llama.cpp 表现更好。
推理
ORT 在 float16 下的性能提升
经过优化的 CUDA 在提示吞吐量(即模型根据输入提示处理和生成响应的速度)方面比 PyTorch Compile 快 高达 7.39 倍。我们还观察到,与 Llama.cpp 相比,ONNX Runtime 在更大的批处理大小和提示长度下显著更快。例如,在批处理大小为 16、提示长度为 2048 时,它快 高达 13.08 倍。
令牌生成吞吐量是生成的前 256 个令牌的平均吞吐量。使用 float16 的 ONNX Runtime 平均比 torch.compile 快 6.6 倍,最高可达 18.55 倍。它也比 Llama.cpp 快 高达 1.64 倍。
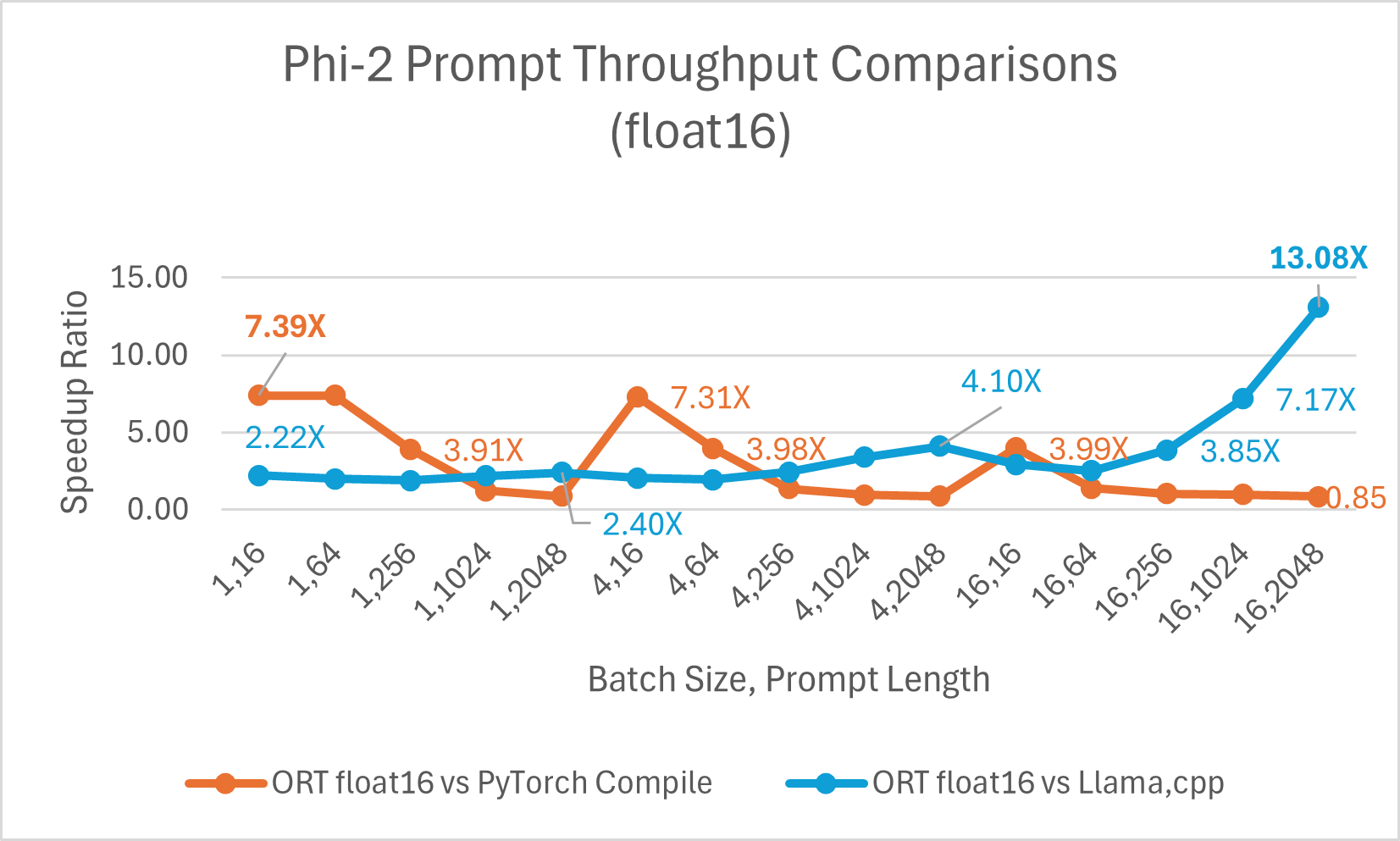
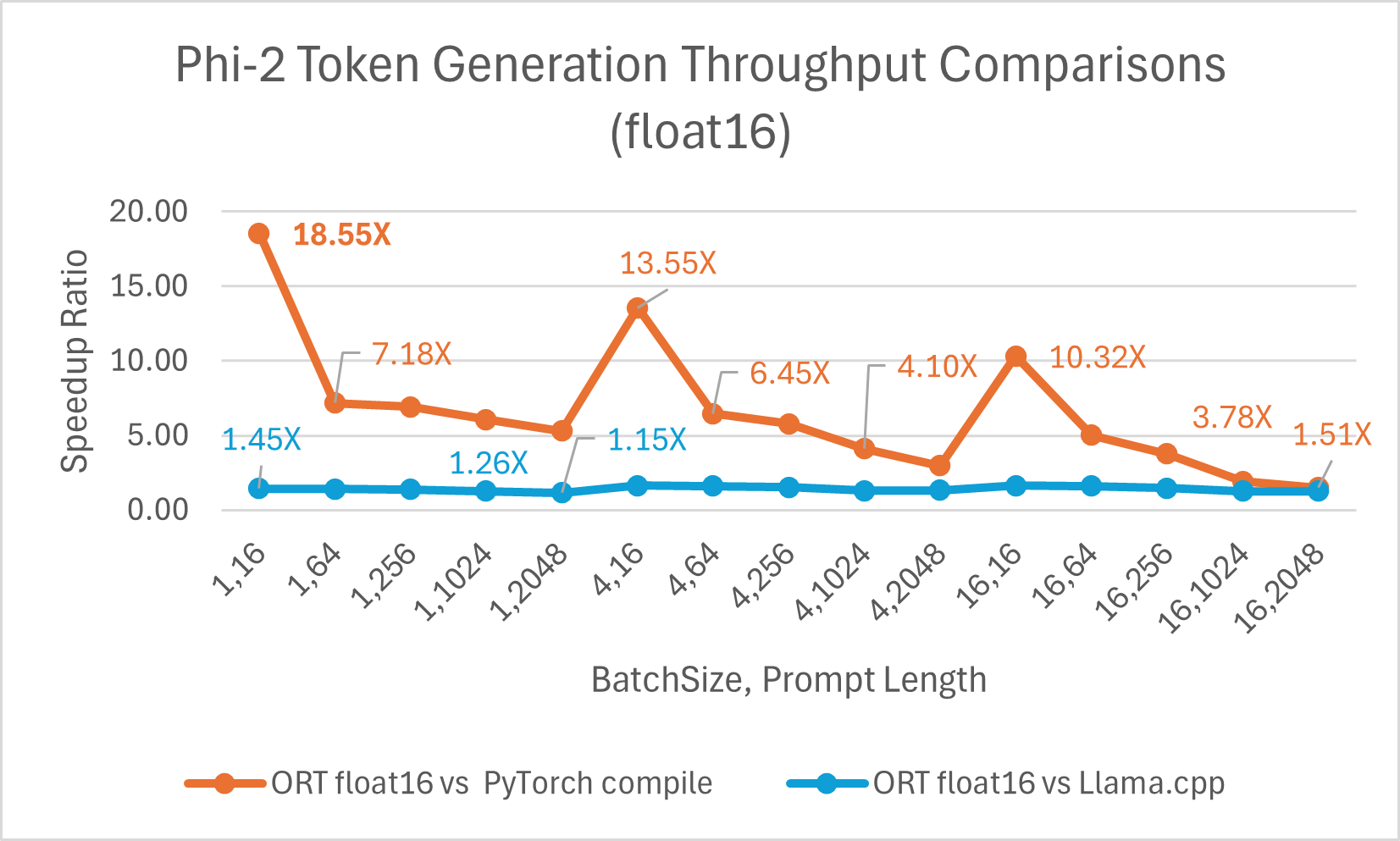
ORT 在 int4 下的性能提升
ORT 支持 int4 量化。与 PyTorch 相比,使用 int4 量化的 ORT 性能可提升 高达 20.48 倍。它平均比 Llama.cpp 好 3.9 倍,对于大序列长度,快 高达 13.42 倍。由于 GemV 的特殊内核,使用 int4 量化的 ONNX Runtime 通常在批处理大小为 1 时表现最佳。
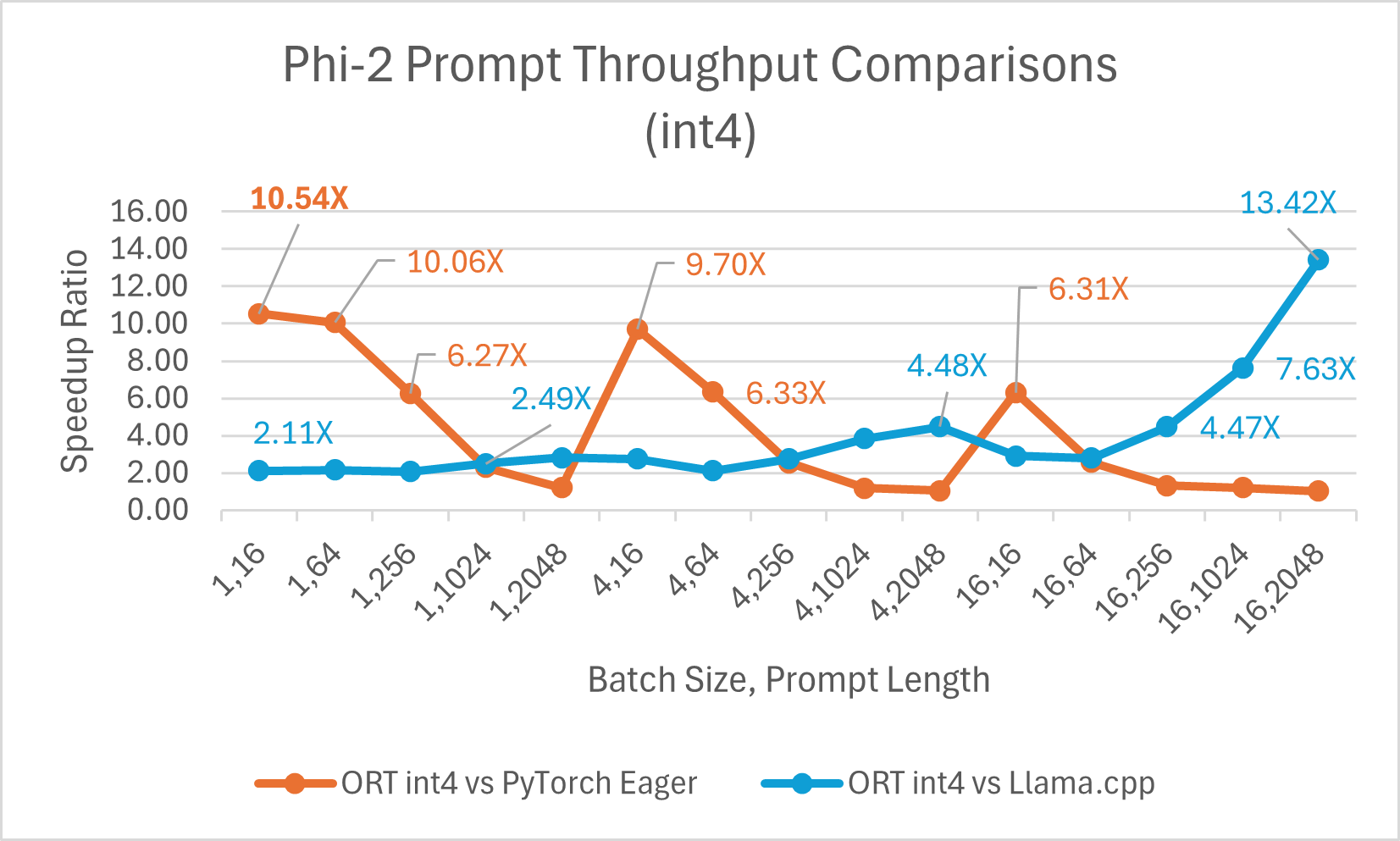
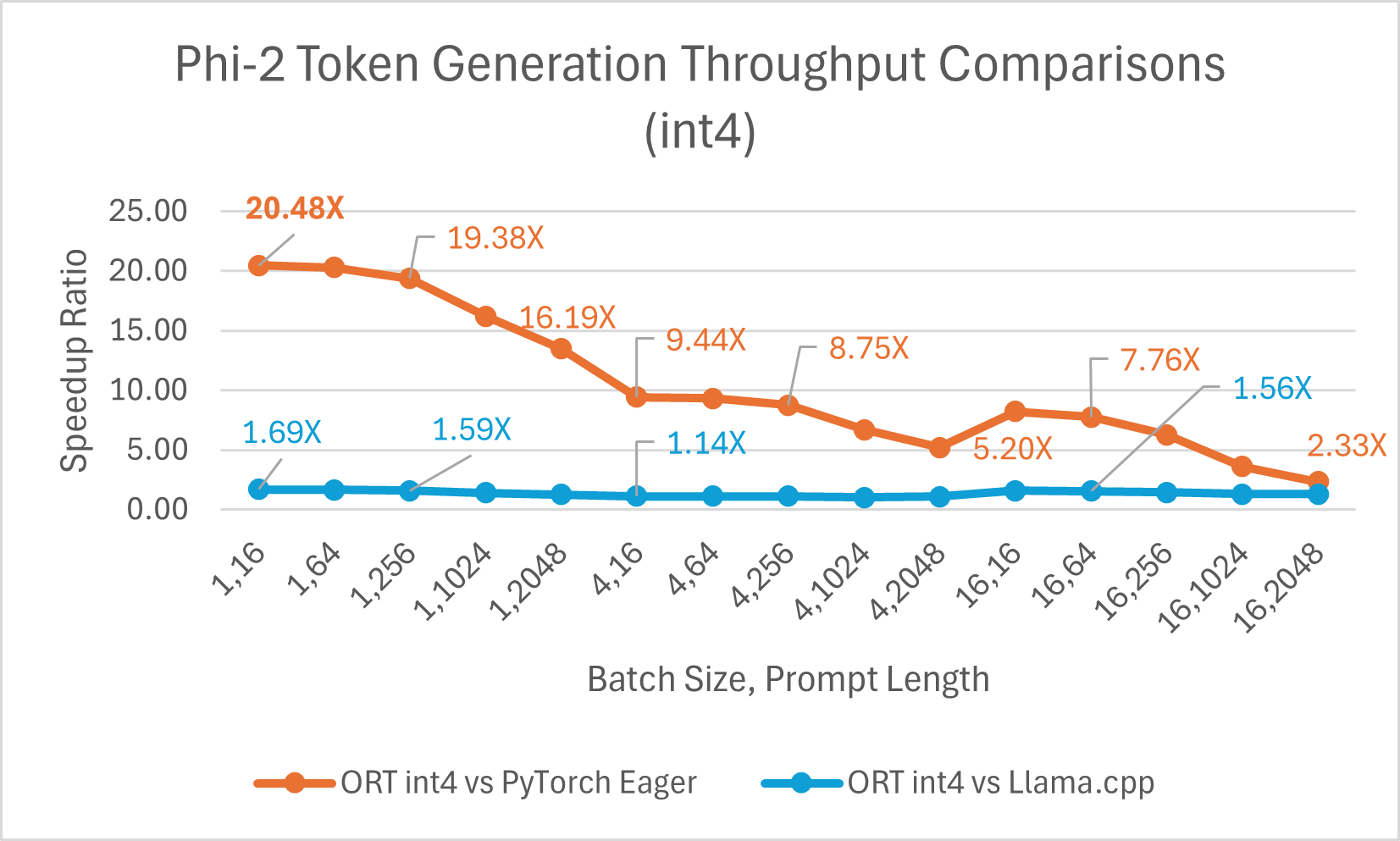
- Phi-2 基准测试在 1 块 A100 GPU 上进行 (SKU: Standard_ND96amsr_A100_v4)。使用的软件包:torch: 2.3.0. dev20231221+cu121; pytorch-triton: 2.2.0+e28a256d71; ort-nightly-gpu: 1.17.0.dev20240118001; deepspeed: 0.12
- 批处理是一组不同长度的输入句子;提示长度指输入文本的大小或长度。
这是使用 Olive 对 Phi-2 进行优化的示例,它利用本博客中强调的 ONNX Runtime 优化,并使用易于使用的硬件感知模型优化工具 Olive。
训练
除了推理,ONNX Runtime 还为 Phi-2 和其他大型语言模型 (LLM) 提供训练加速。ORT 训练是 PyTorch 生态系统的一部分,可通过 torch-ort python 包作为 Azure Container for PyTorch (ACPT) 的一部分提供。它提供灵活且可扩展的硬件支持,同一模型和 API 可与 NVIDIA 和 AMD GPU 配合使用。ORT 通过优化的内核和内存优化来加速训练,这在减少大型模型训练的端到端训练时间方面显示出显著的收益。这涉及到修改模型中的几行代码,以使用 ORTModule API 对其进行封装。它还可以与 DeepSpeed 和 Megatron 等流行的加速库组合使用,以实现更快、更高效的训练。
Open AI 的 Triton 是一种领域特定语言和编译器,用于编写高效的自定义深度学习原语。ORT 支持 Open AI Triton 集成 (ORT+Triton),其中所有逐元素运算符都转换为 Triton ops,并且 ORT 在 Triton 中创建自定义融合内核。
ORT 还执行稀疏性优化,以评估输入数据的稀疏性并利用这种稀疏性进行图优化。这减少了计算 FLOP 要求并提高了性能。
基于低秩适配器 (LoRA) 的微调通过仅训练少量额外参数(适配器)同时冻结原始模型的权重,使训练更高效。这些适配器使模型适应特定任务。量化和 LoRA (QLoRA) 将量化与 LoRA 结合,其中权重使用更少的位数表示,同时保留模型的性能和质量。ONNX Runtime 训练与 LoRA 和 QLoRA 结合,为 LLM 提供内存效率和训练时间加速的收益。LoRA 和 QLoRA 技术使 LLM 等超大型模型能够适应 GPU 内存,从而高效完成训练。
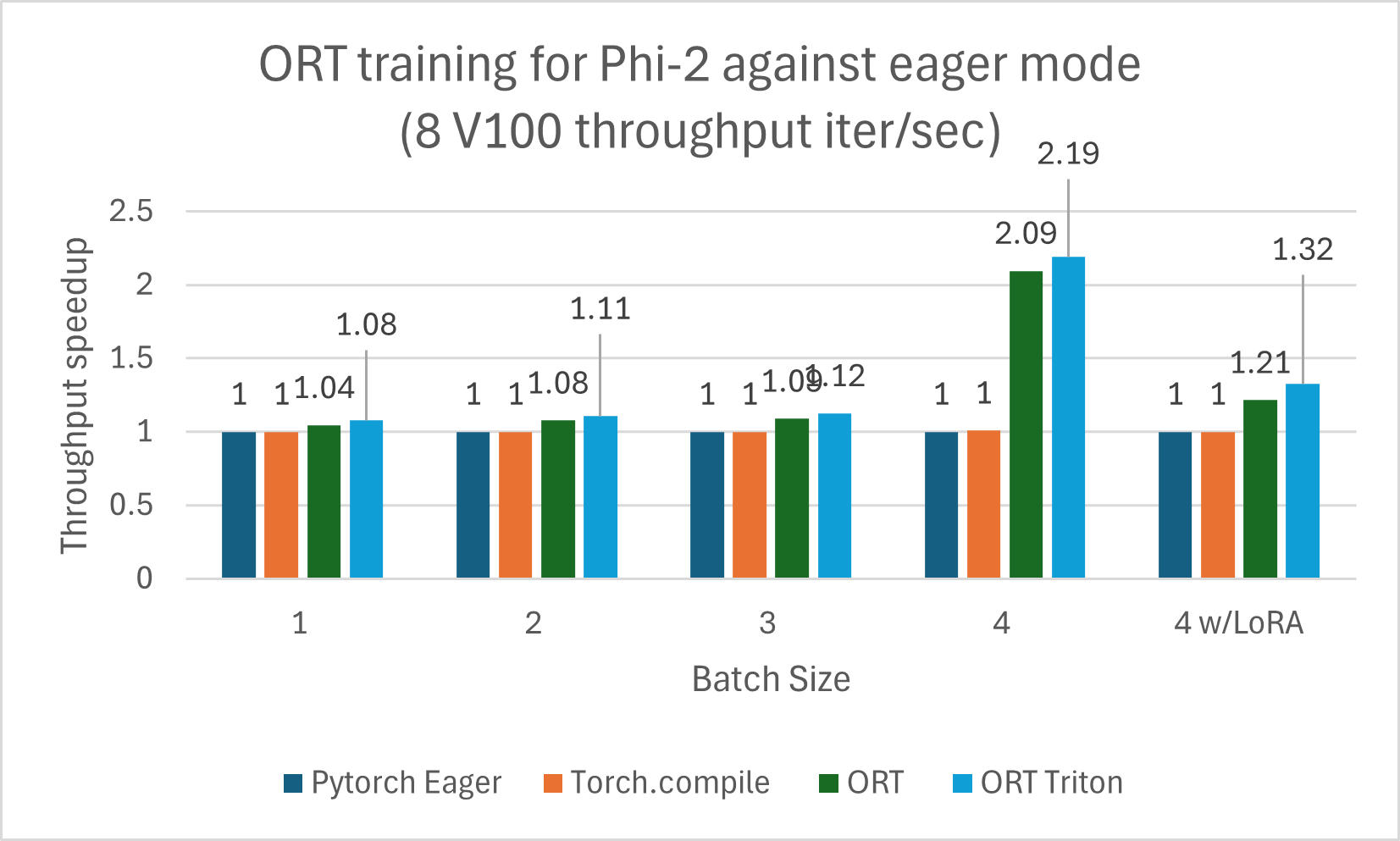
使用 ORT 训练的 Phi-2 模型与 PyTorch Eager 模式和 torch.compile 相比显示出性能提升。Phi-2 使用合成和网络数据集的混合进行训练。我们测量了与 ORT 和 ORT+Triton 模式的性能提升,并且随着批处理大小的增加,提升也随之增加。该模型使用 DeepSpeed Stage-2 训练了 5 个 epoch,在 wikitext 数据集上使用递增的批处理大小。V100 和 A100 的性能提升总结在下面的图表中。
训练基准测试在 8 块 V100 上运行,并测量了每秒迭代次数的吞吐量(越高越好)
以下训练基准测试在 2 块 A100 上运行,并测量了每秒迭代次数的吞吐量(越高越好)
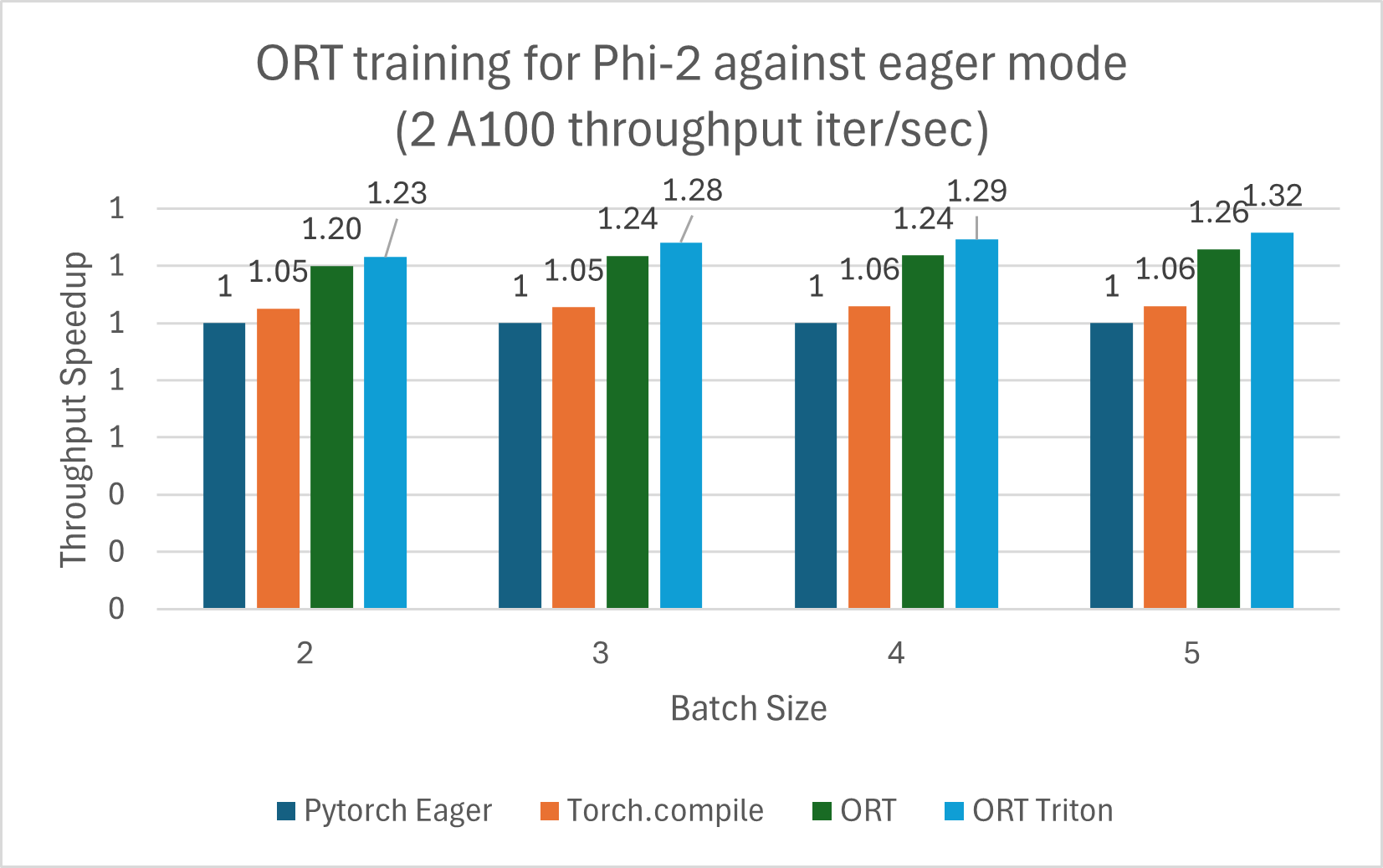 注:使用了 PyTorch Stable 2.2.0 和 ONNXRuntime Training: Stable 1.17.0 版本。
注:使用了 PyTorch Stable 2.2.0 和 ONNXRuntime Training: Stable 1.17.0 版本。 Mistral
推理
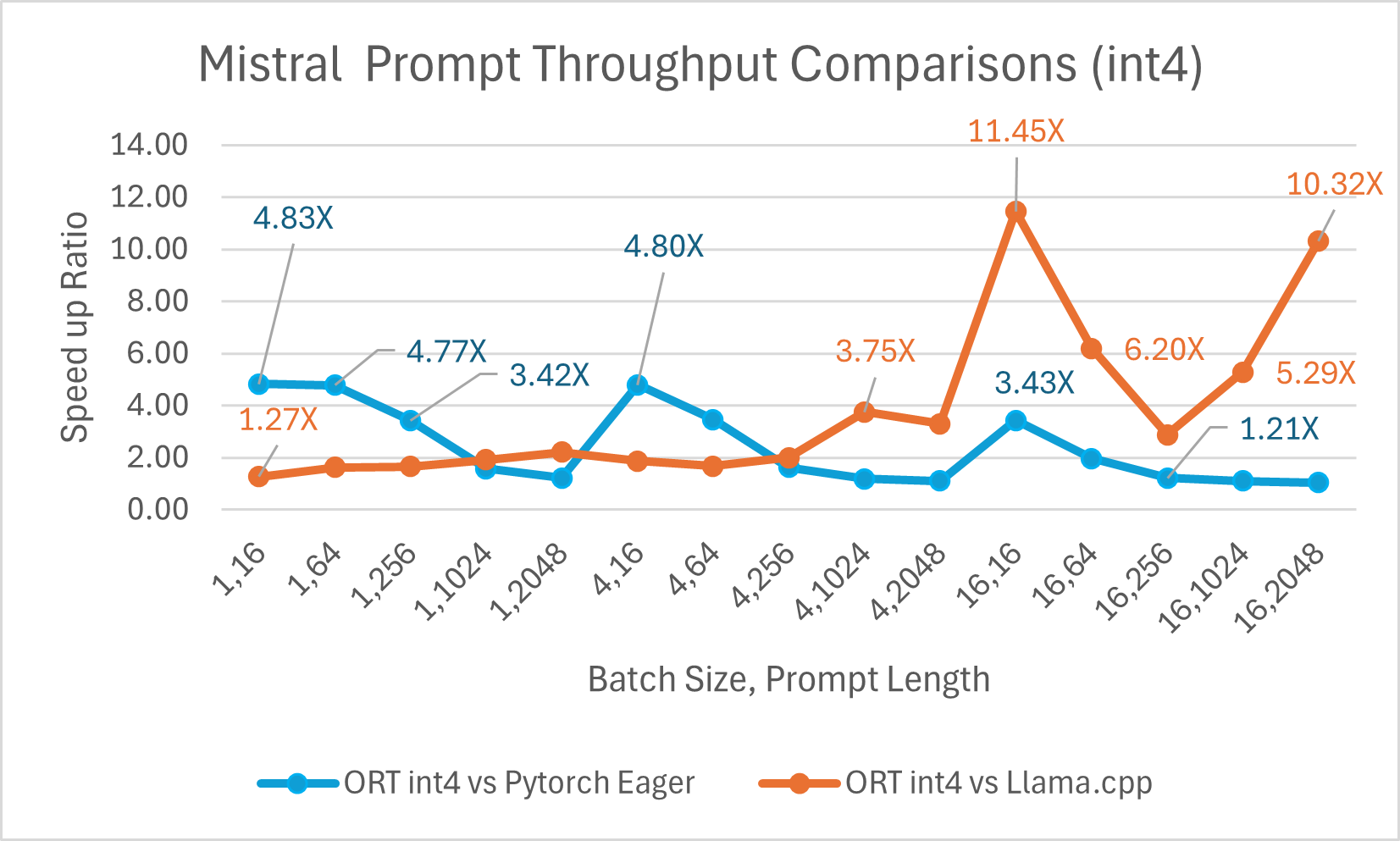
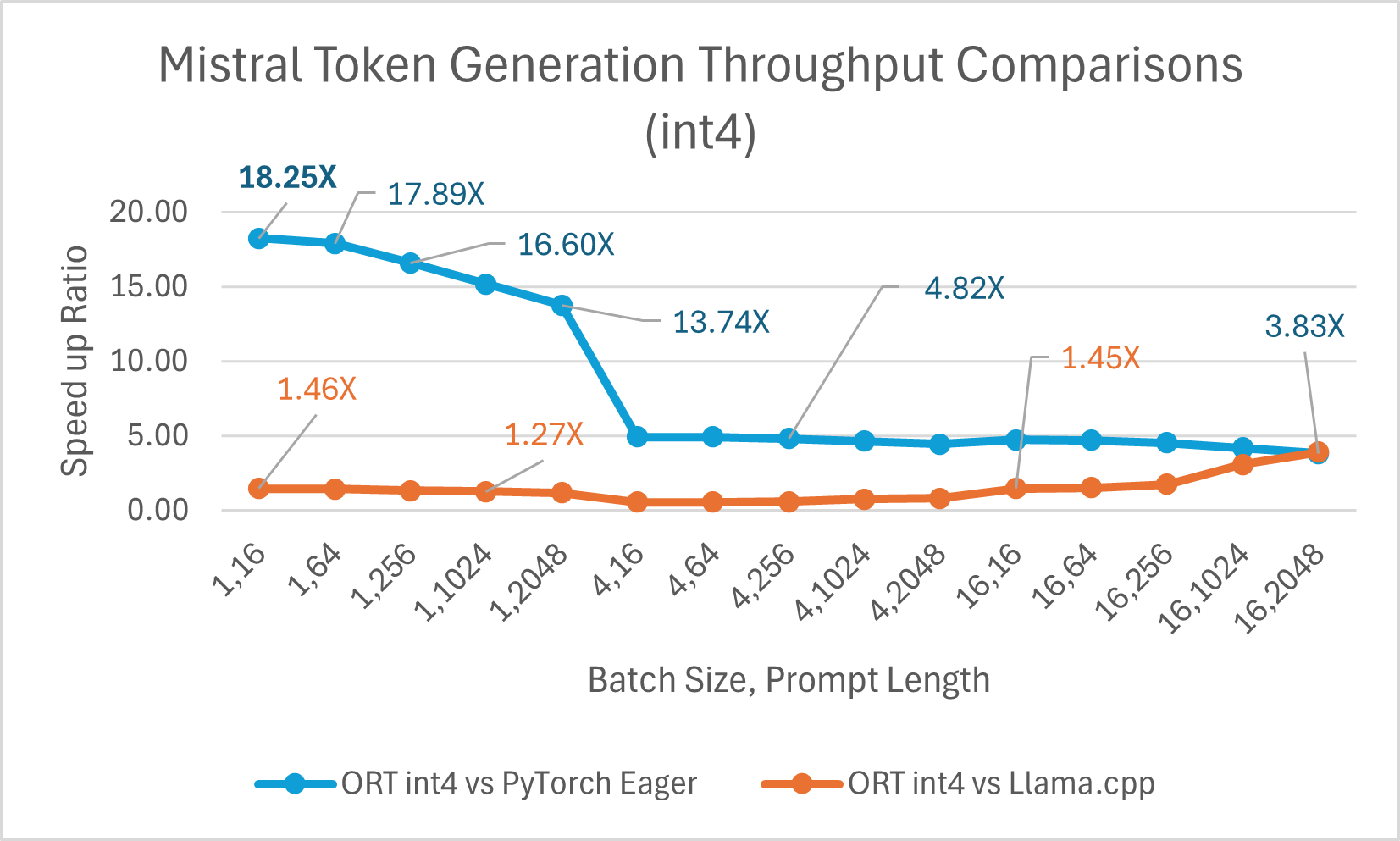
Mistral7B 是一个预训练的生成式文本大型语言模型 (LLM),拥有 70 亿参数。ONNX Runtime 显著提升了 Mistral 在 float16 和 int4 模型下的推理性能。使用 float16 时,ONNX Runtime 比 Llama.cpp 快 高达 9.46 倍。对于批处理大小为 1 的 int4 量化,令牌生成吞吐量显著提高,比 PyTorch Eager 快 高达 18.25 倍。
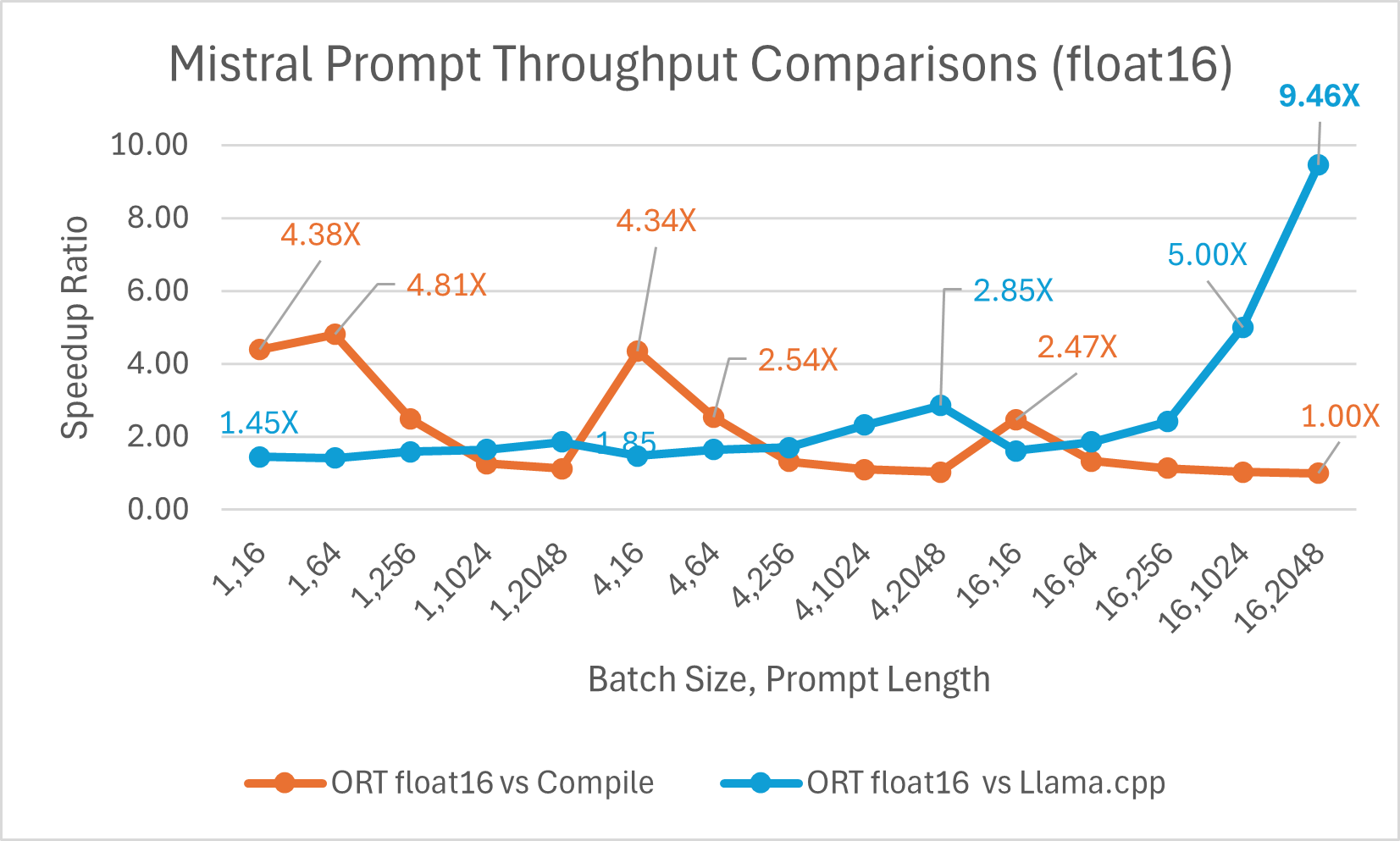
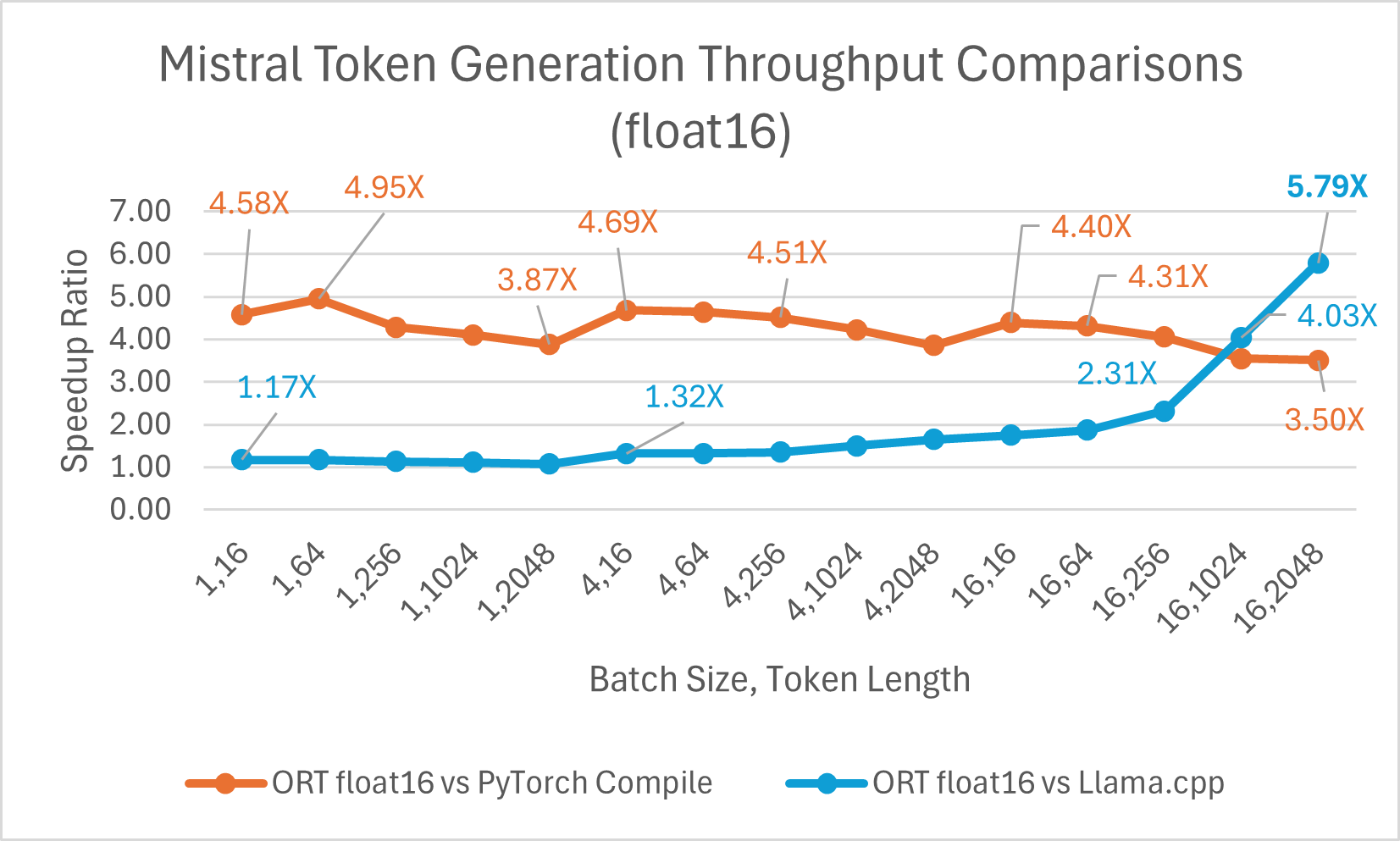
您现在可以在 Huggingface 这里获取优化后的 Mistral 模型。
训练
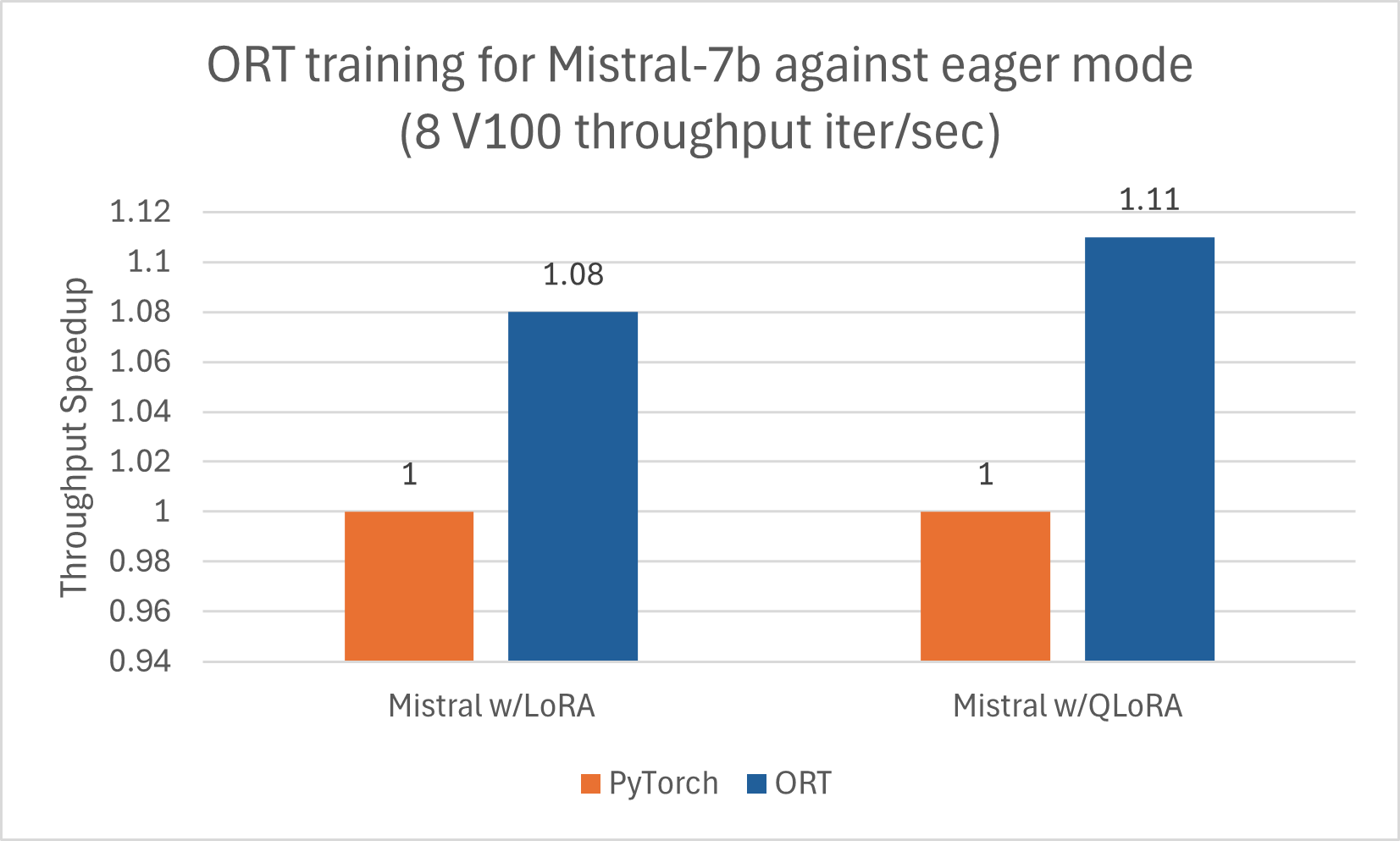
与 Phi-2 类似,Mistral 也受益于使用 ORT 进行训练加速。我们使用以下配置训练了 Mistral-7B,以观察 ORT 的性能提升,包括与 LoRA 和 QLoRA 结合使用时。该模型使用 DeepSpeed Stage-2 训练了 5 个 epoch,在 wikitext 数据集上使用批处理大小 1。
CodeLlama
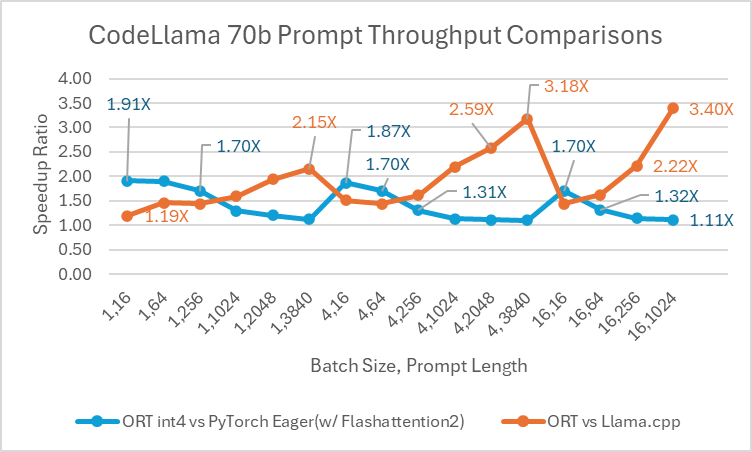
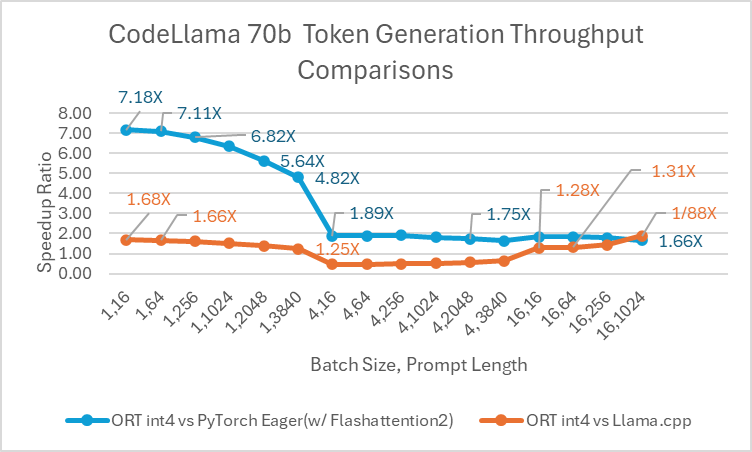
Codellama-70B 是一个基于 Llama-2 平台开发的专注于编程的模型。该模型可以生成代码并以自然语言围绕代码进行讨论。由于 CodeLlama-70B 是一个经过微调的 Llama 模型,因此可以直接应用现有的优化。我们将一个 4 位量化的 ONNX 模型与 PyTorch Eager 和 Llama.cpp 进行了比较。对于提示吞吐量,ONNX Runtime 在所有批处理大小下都比 PyTorch Eager 至少快 1.4 倍。ONNX Runtime 生成令牌的平均速度比 PyTorch Eager 在任何批处理大小下都高 3.4 倍,比 Llama.cpp 在批处理大小为 1 时高 1.5 倍。
SD-Turbo 和 SDXL-Turbo
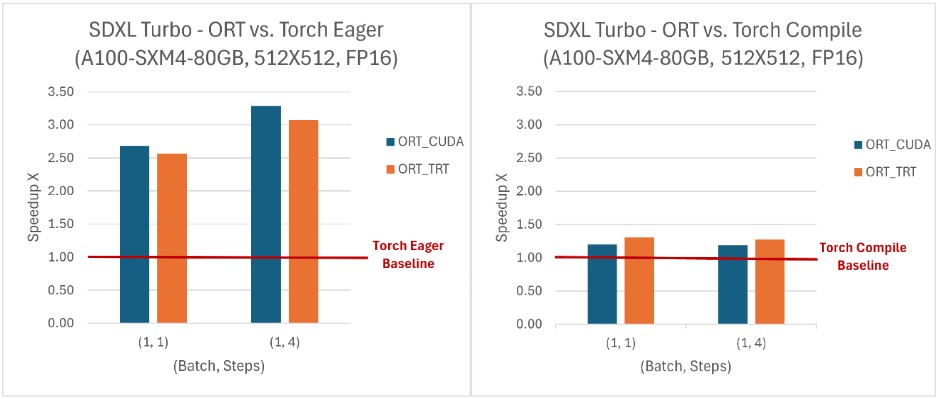
ONNX Runtime 在与 SD Turbo 和 SDXL Turbo 结合使用时提供了推理性能优势,并且还使得这些模型可以在 Python 之外的语言中(如 C# 和 Java)访问。在所有评估的(批处理大小,步数)组合中,ONNX Runtime 的吞吐量均高于 PyTorch,其中 SDXL Turbo 模型的吞吐量提升高达 229%,SD Turbo 模型提升120%。ONNX Runtime CUDA 在处理动态形状方面表现尤为出色,同时在静态形状方面也显示出相对于 PyTorch 的显著优势。
要了解更多关于使用 ONNX Runtime 加速 SD-Turbo 和 SDXL-Turbo 推理的信息,请查看我们最近与 Hugging Face 合作发布的博客。
Llama-2
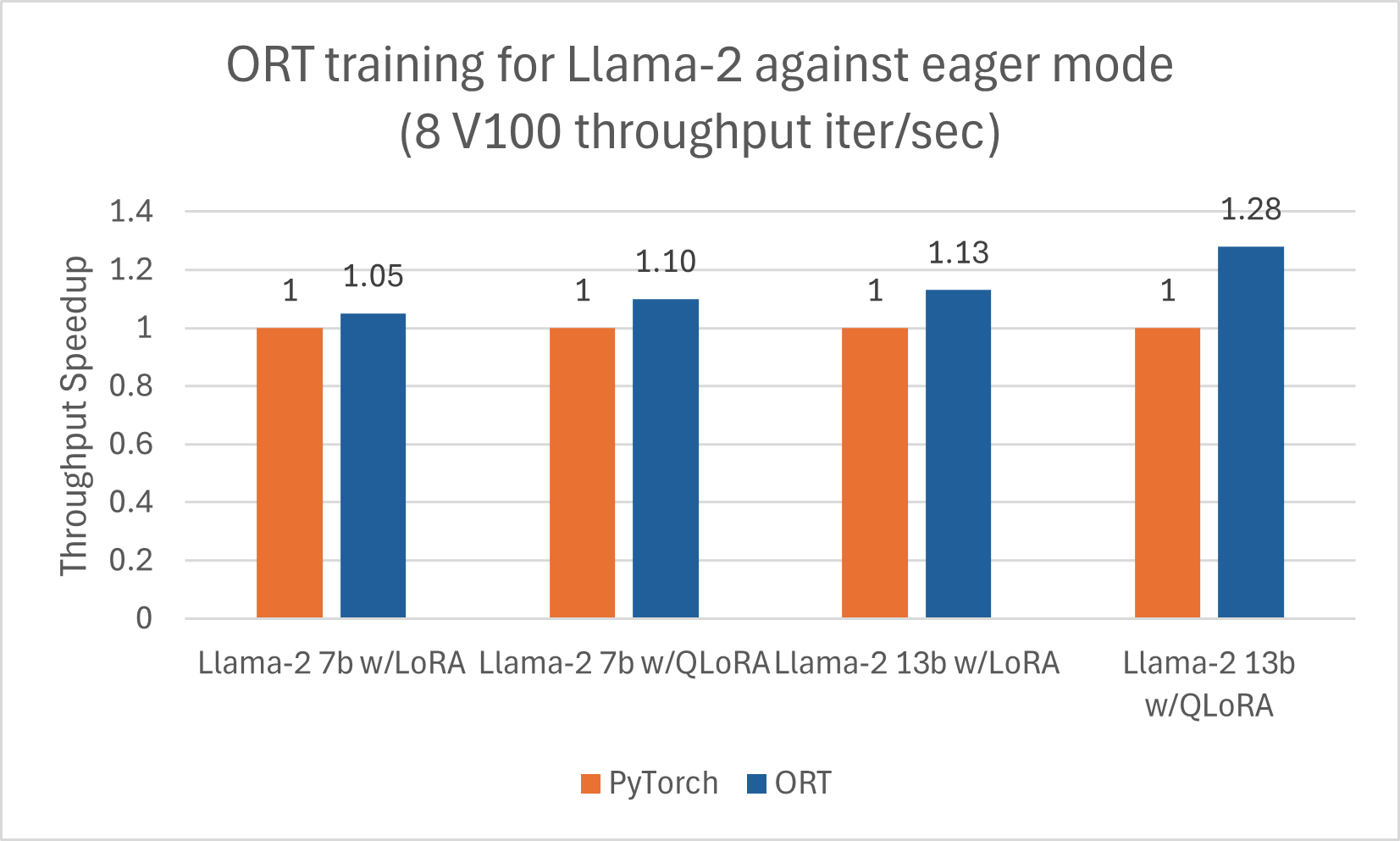
我们发布了另一篇博客,详细介绍了使用 ORT 对 Llama-2 进行推理的改进这里。此外,Llama-2-7B 和 Llama-2-13B 在使用 ORT 进行训练时显示出良好的性能提升,尤其是在与 LoRA 和 QLoRA 结合使用时。这些脚本可以作为使用 Optimum 和 ORT 微调 Llama-2 的示例。以下数据是 Llama-2 模型使用 DeepSpeed Stage-2 进行 5 个 epoch 训练,批处理大小为 1,在 wikitext 数据集上的结果。
Orca-2
推理
Orca-2 是一个仅用于研究的系统,可在处理用户提供的数据推理、文本理解、数学问题求解和文本摘要等任务中提供一次性答案。Orca-2 有两个版本(70 亿和 130 亿参数);两者都是通过在定制的、高质量的人工数据上微调各自的 Llama-2 基础模型而制成的。ONNX Runtime 通过使用图融合和内核优化(如 Llama-2 的优化)来帮助优化 Orca-2 推理。
ORT 在 int4 下的性能提升
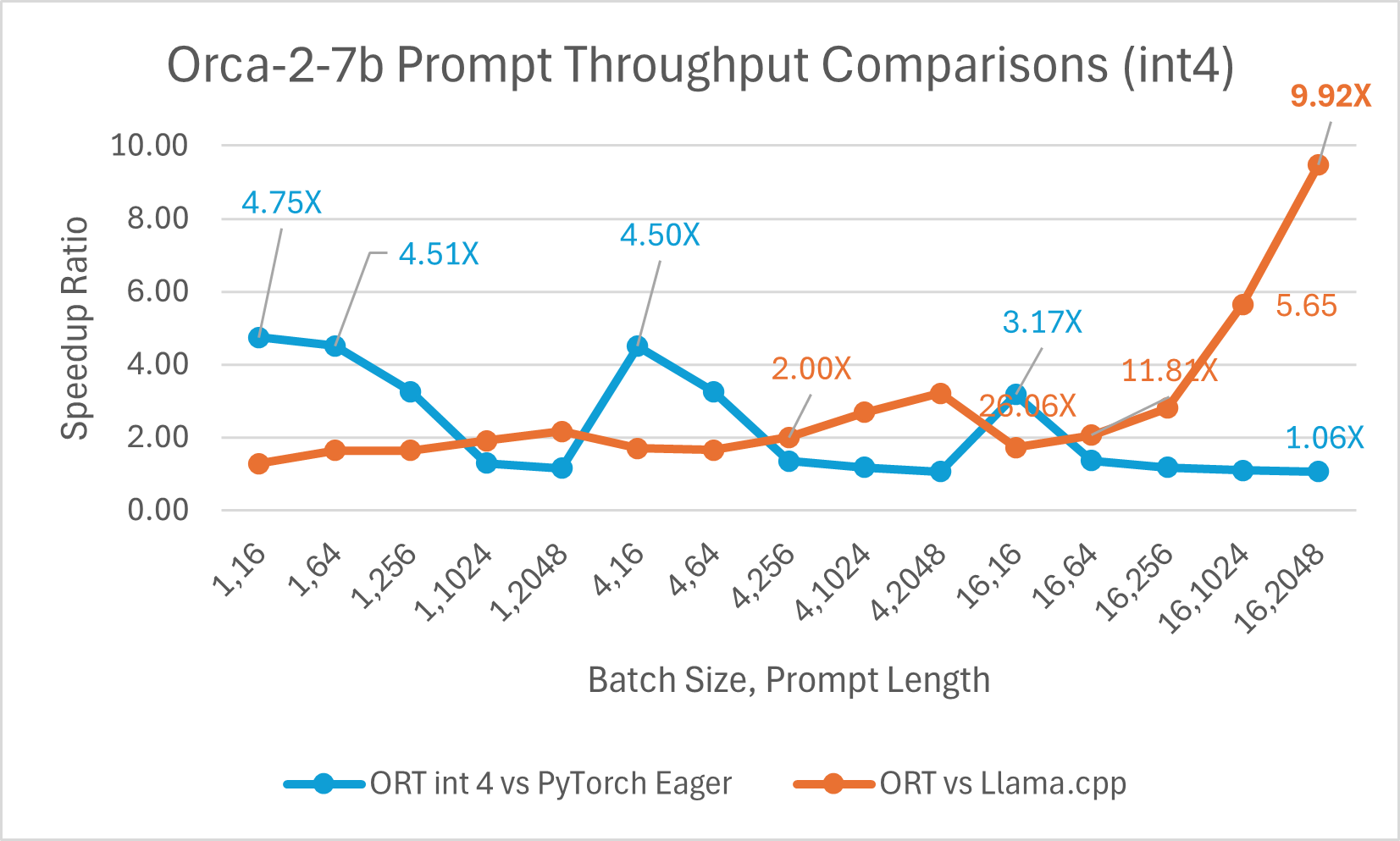
Orca-2-7B int4 量化性能比较显示,与 PyTorch 相比,提示吞吐量性能提升高达 26 倍,令牌生成吞吐量提升高达 16.5 倍。与 Llama.cpp 相比,提示吞吐量提升超过 4.75 倍,令牌生成吞吐量提升 3.64 倍。
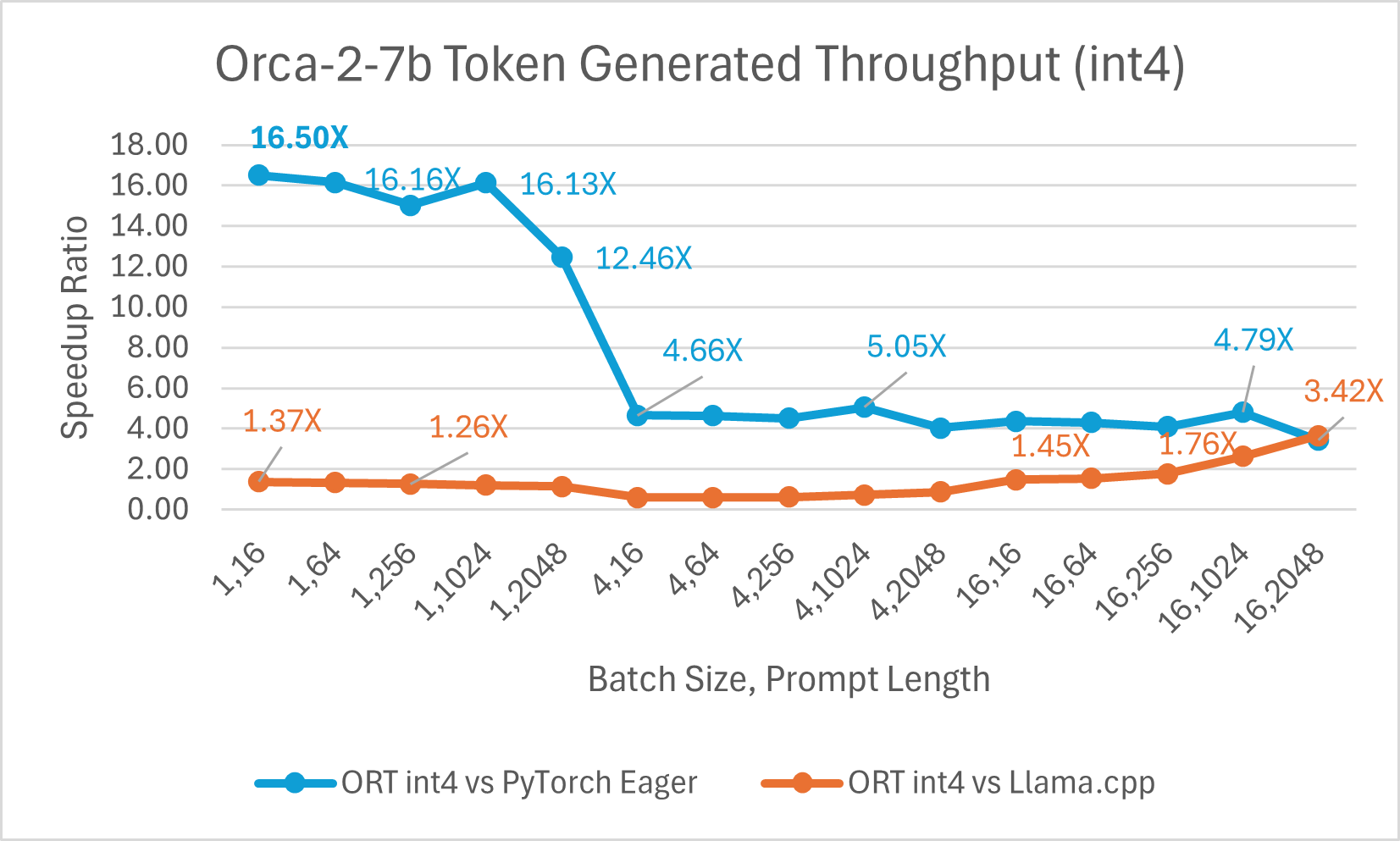
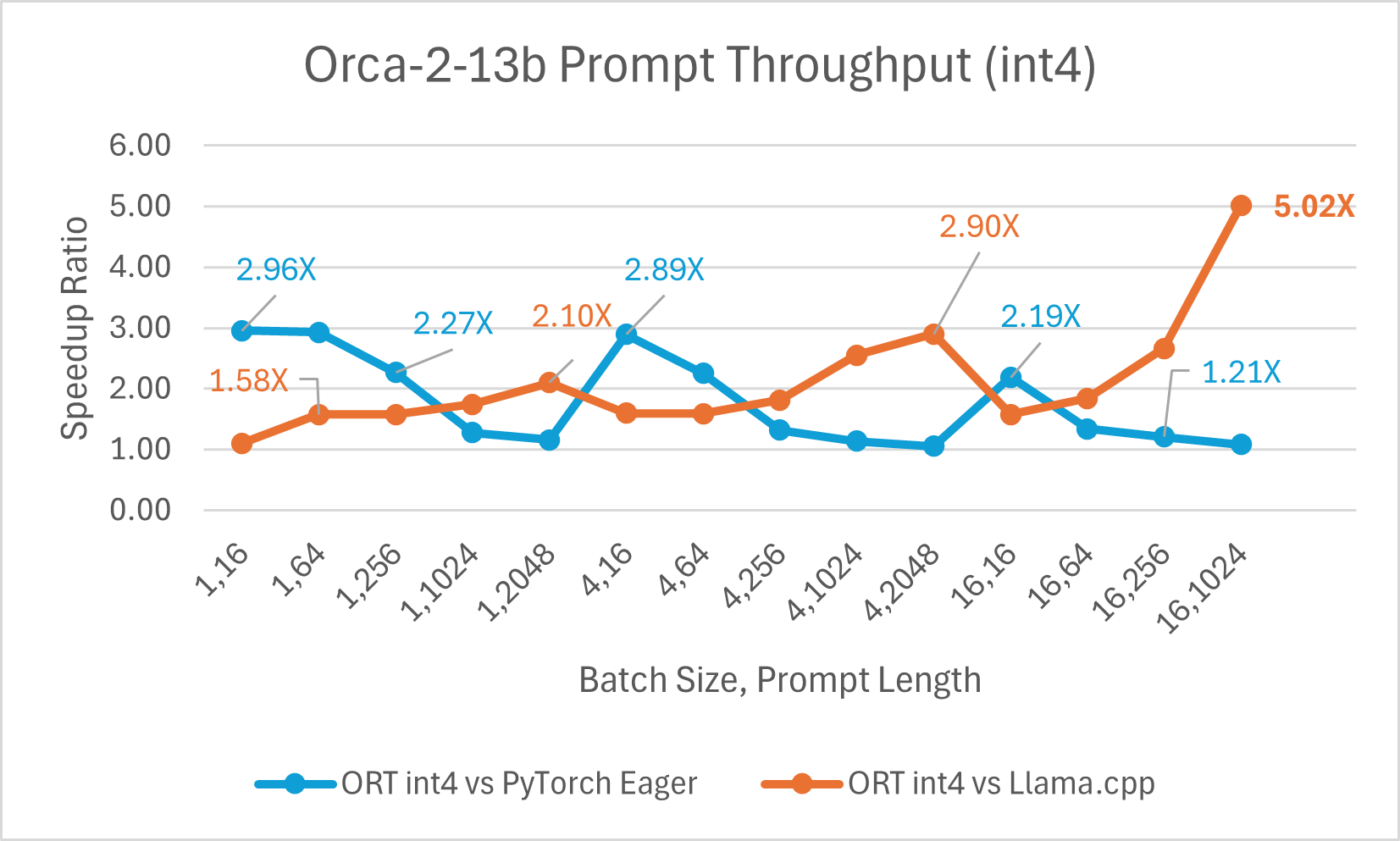
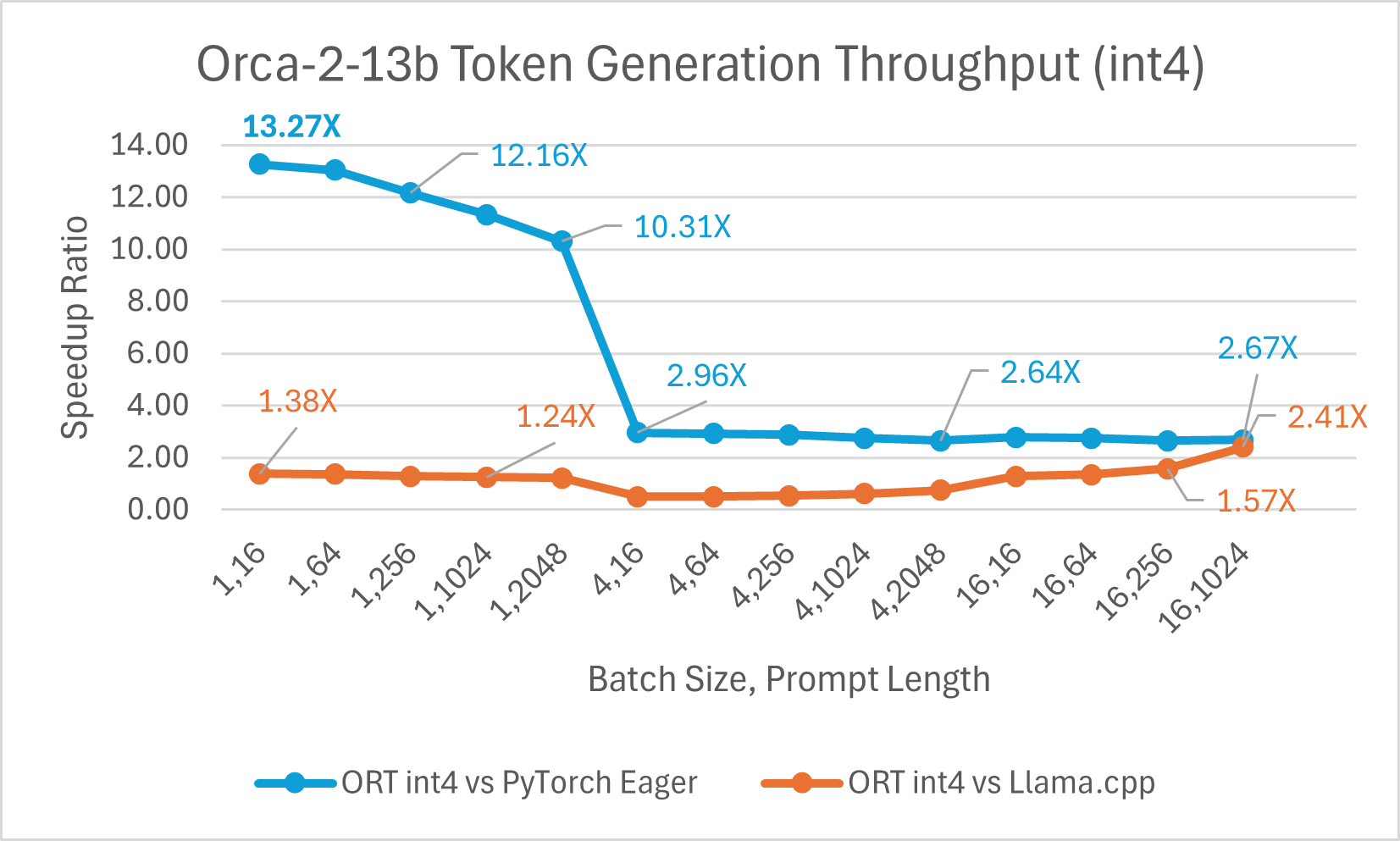
使用 ONNX Runtime float16 的 Orca-2 7b 性能比较也显示出在提示和令牌生成吞吐量方面的显著提升。
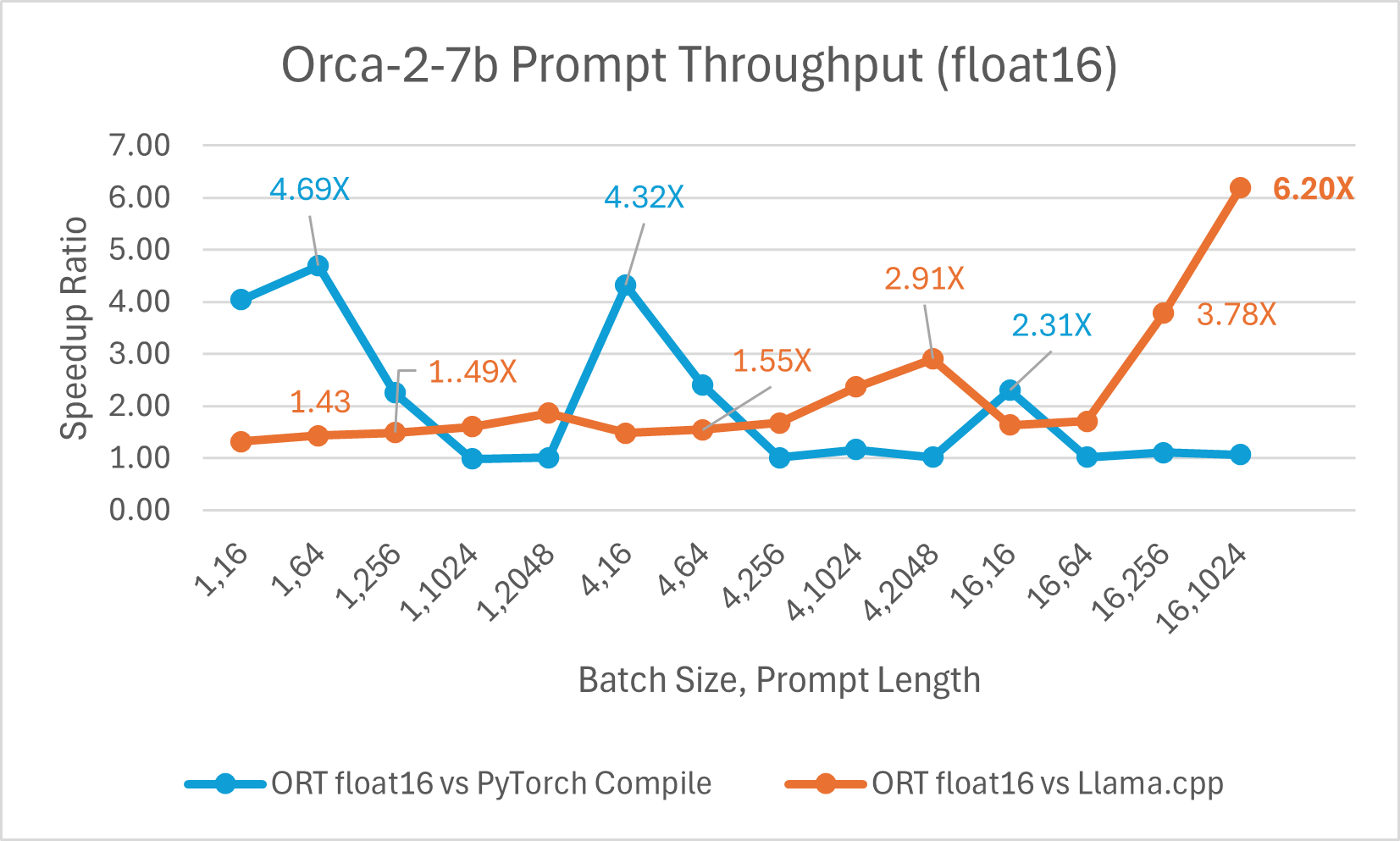
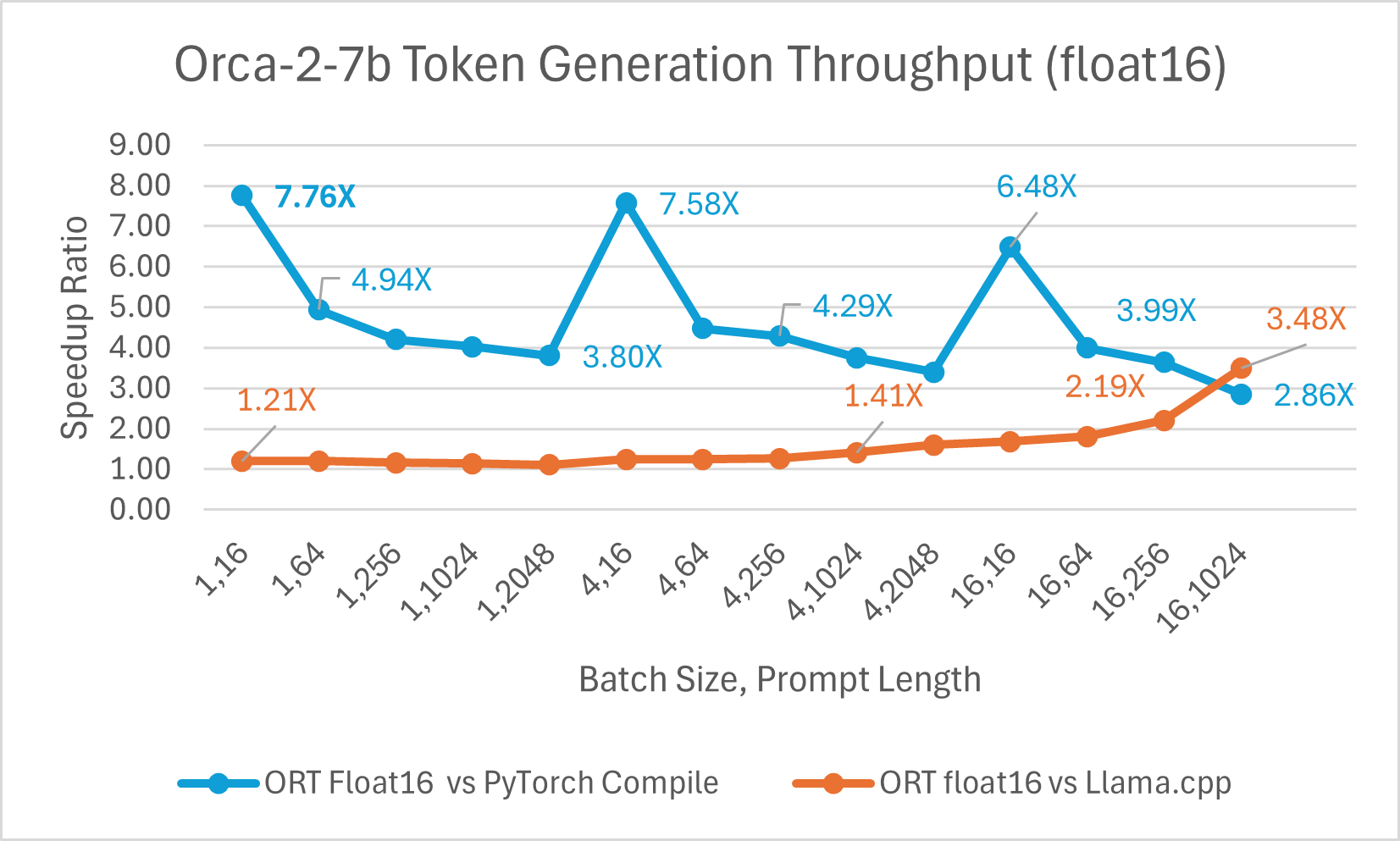
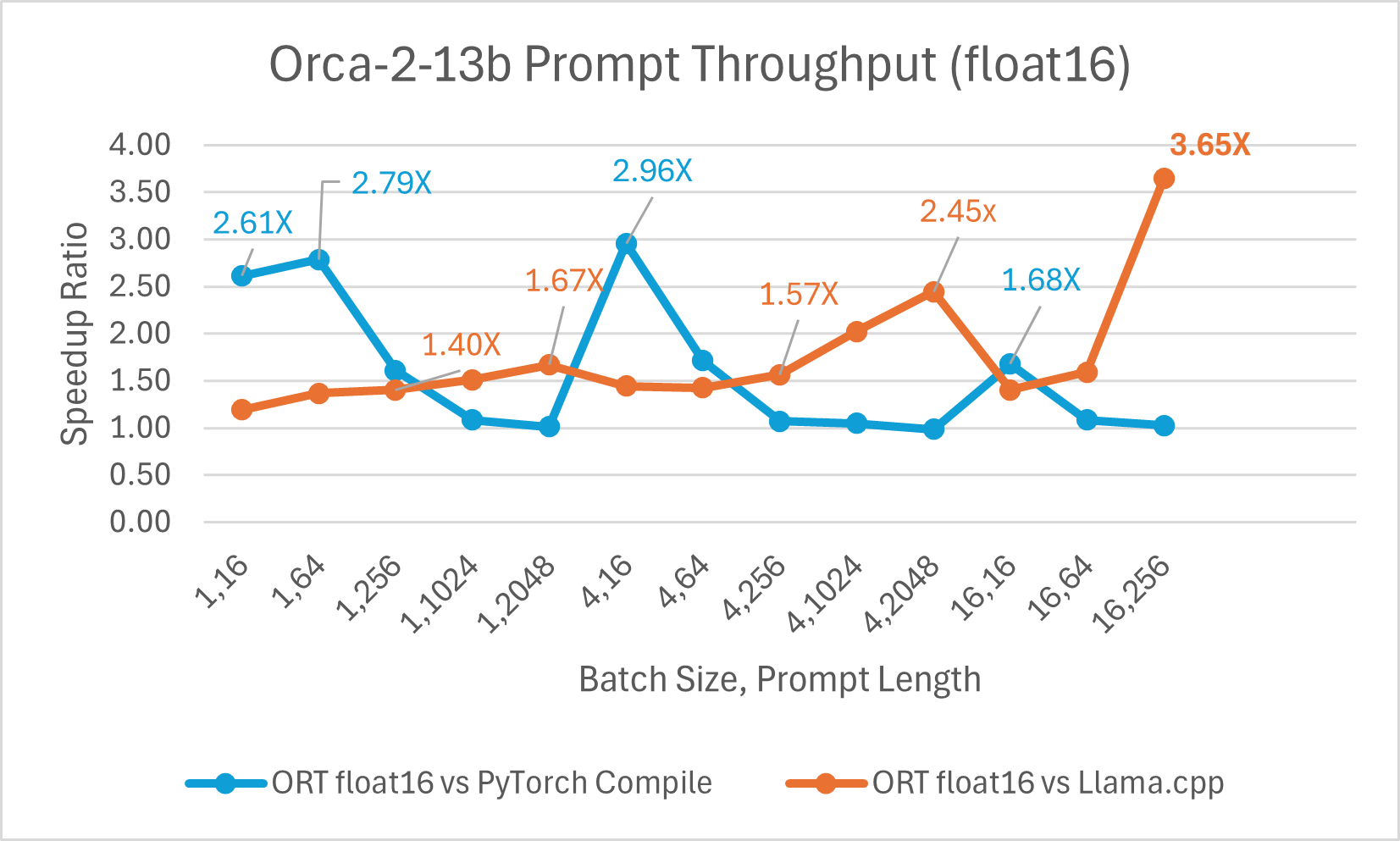
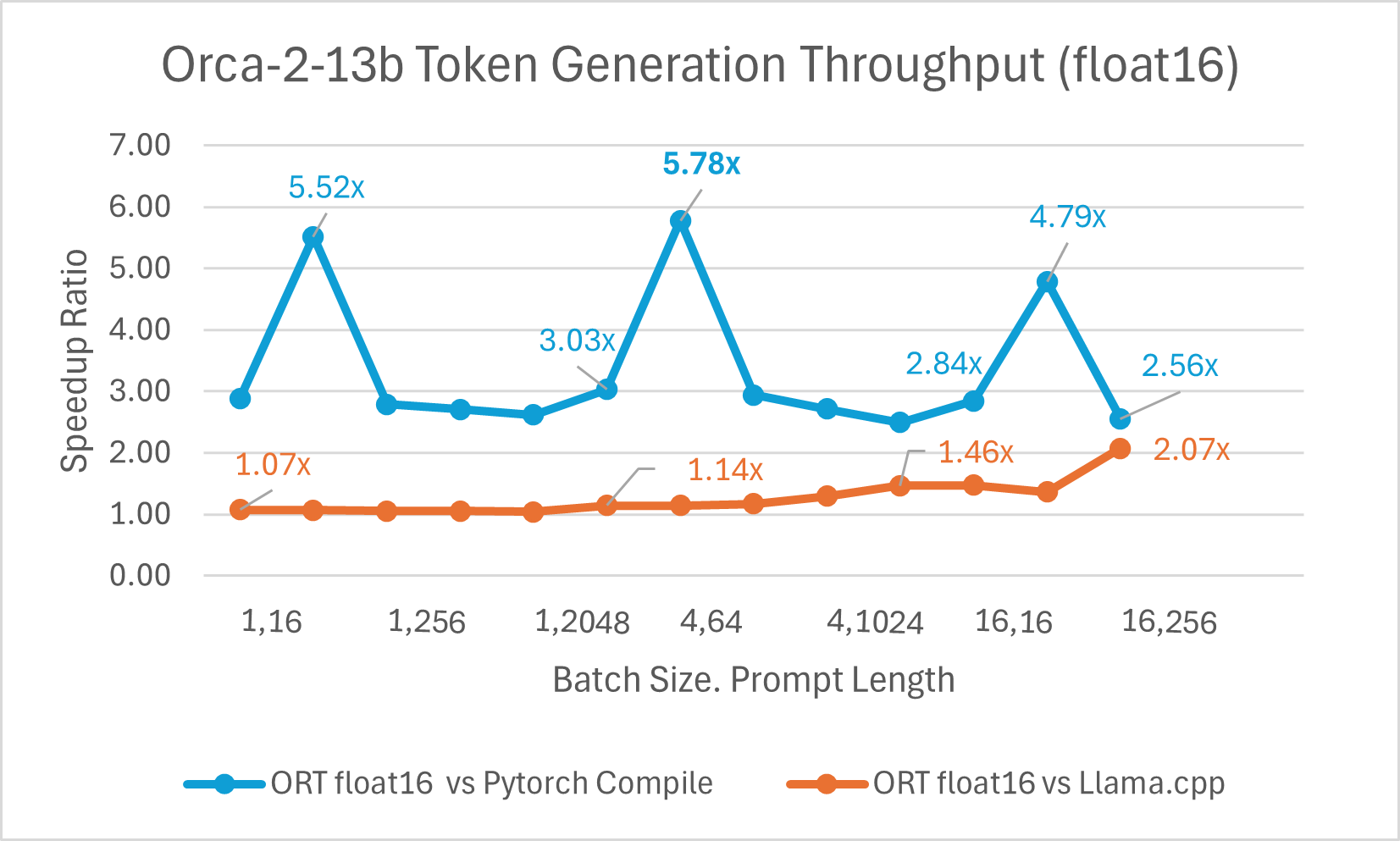
Orca-2 基准测试在 1 块 A100 GPU 上完成,SKU: Standard_ND96amsr_A100_v4,软件包:torch 2.2.0, triton 2.2.0, onnxruntime-gpu 1.17.0, deepspeed 0.13.2, llama.cpp - commit 594fca3fefe27b8e95cfb1656eb0e160ad15a793, transformers 4.37.2
训练
Orca-2-7B 也受益于使用 ORT 进行训练加速。我们使用 LoRA 并启用稀疏性优化,对 Orca-2-7B 模型进行了序列长度为 512 的训练,并观察到良好的性能提升。以下数据是 Orca-2-7B 模型使用 DeepSpeed Stage-2 进行 5 个 epoch 训练,批处理大小为 1,在 wikitext 数据集上的结果。
 使用 ACPT 镜像:nightly-ubuntu2004-cu118-py38-torch230dev:20240131
使用 ACPT 镜像:nightly-ubuntu2004-cu118-py38-torch230dev:20240131 Gemma
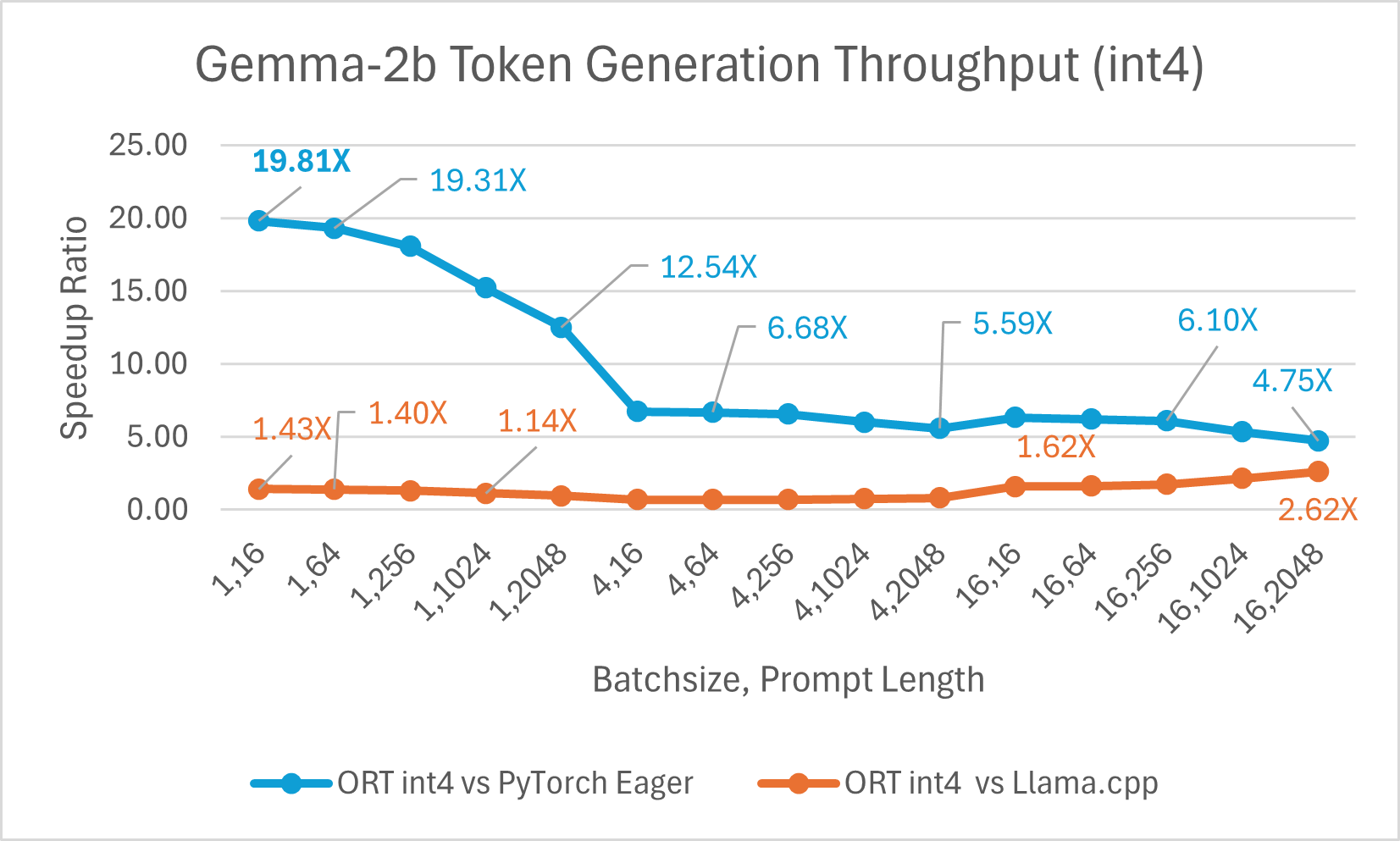
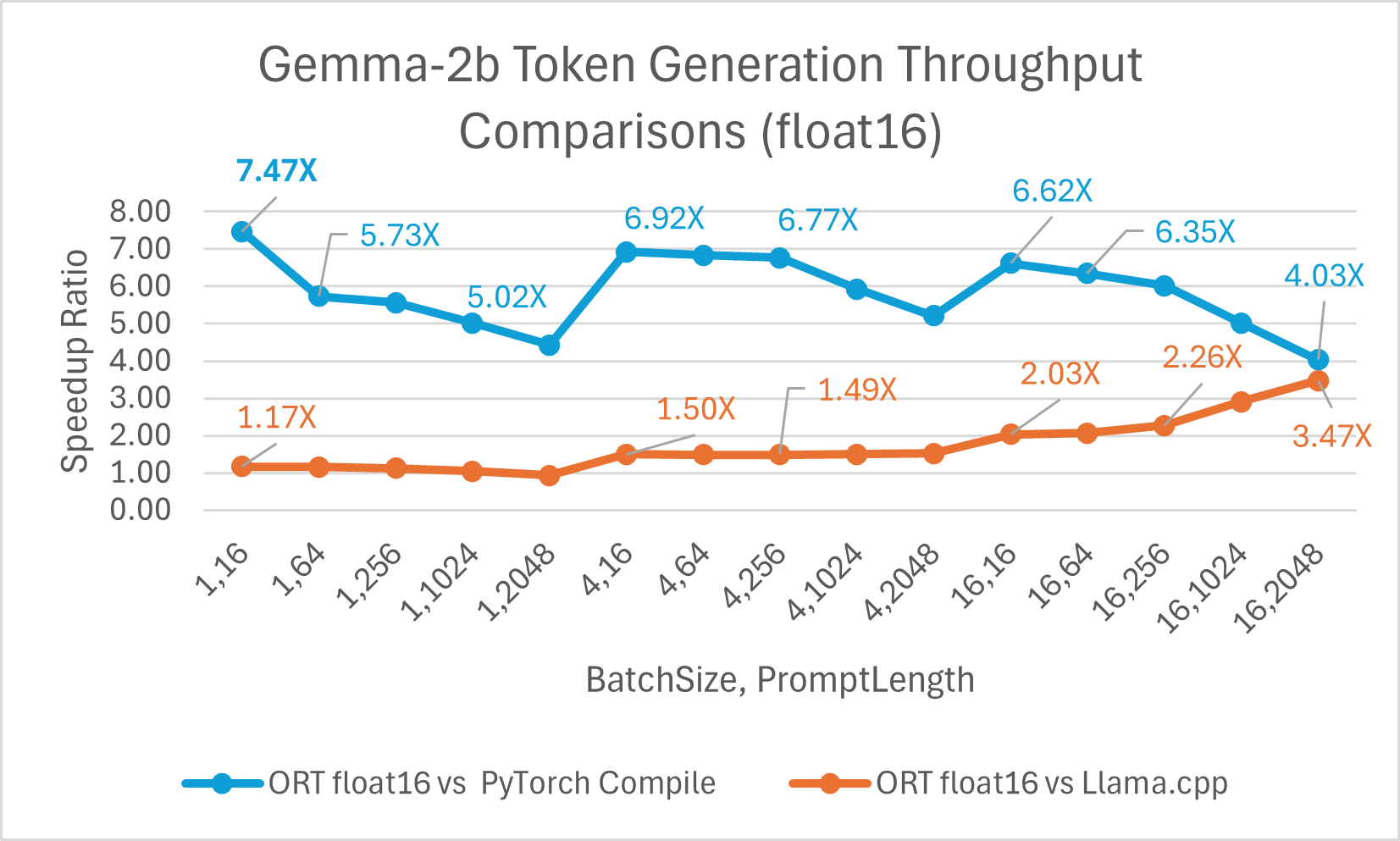
Gemma 是一个轻量级开放模型系列,由 Google 用于创建 Gemini 模型的研究和技术构建而成。它提供两种尺寸:2B 和 7B。每种尺寸都发布了预训练和指令微调版本。ONNX Runtime 可用于优化和高效运行任何开源模型。我们对 Gemma-2B 模型进行了基准测试,结果显示使用 float16 的 ONNX Runtime 比 PyTorch Compile 快高达 7.47 倍,比 Llama.cpp 快高达 3.47 倍。使用 int4 量化的 ORT 比 PyTorch Eager 快高达 19.81 倍,比 Llama.cpp 快 2.62 倍。
总结
总之,ONNX Runtime (ORT) 为包括 Phi-2、Mistral、CodeLlama、SDXL-Turbo、Llama-2、Orca-2 和 Gemma 在内的多个模型提供了显著的性能改进。ORT 提供最先进的融合和内核优化,包括对 float16 和 int4 量化的支持,从而实现更快的推理速度和更低的成本。在提示和令牌生成吞吐量方面,ORT 优于 PyTorch 和 Llama.cpp 等其他框架。ORT 在训练大型语言模型 (LLM) 方面也显示出显著优势,批处理大小越大,性能提升越明显,并且与最先进的技术结合良好,可实现高效的大型模型训练。