ONNX Runtime 1.17:支持 CUDA 12、Phi-2 优化、WebGPU 及更多精彩功能!
作者
Sophie Schoenmeyer, Parinita Rahi, Kshama Pawar, Caroline Zhu, Chad Pralle, Emma Ning, Natalie Kershaw, Jian Chen2024 年 2 月 28 日
我们最近发布了 ONNX Runtime 1.17 版本,其中包含大量新功能,旨在进一步简化机器学习模型的推理和训练过程,使其在各种平台上的运行速度比以往更快。此版本改进了我们的一些现有功能,并带来了令人兴奋的新功能,例如 Phi-2 优化、通过设备端训练在浏览器中训练模型、支持 WebGPU 的 ONNX Runtime Web 等等。
有关新功能的完整列表以及各种资源,请查看 GitHub 上的 1.17 版本 和我们最近的 1.17.1 补丁版本。
模型优化
ONNX Runtime (ORT) 1.17 版本为多种模型提供了改进的推理性能,例如 Phi-2、Mistral、CodeLlama、Google 的 Gemma、SDXL-Turbo 等,这得益于采用了最先进的融合和内核优化,并支持 float16 和 int4 量化。此版本中新增的 ORT 优化包括注意力(Attention)、多头注意力(Multi-Head Attention)、分组查询注意力(Grouped-Query Attention)和旋转位置嵌入(Rotary Embedding)ORT 内核改进。在提示和令牌生成吞吐量方面,ORT 优于 PyTorch、DeepSpeed 和 Llama.cpp 等其他框架,加速效果高达 20 倍。具体而言,我们观察到 Phi-2 的性能提升高达 20.5 倍,Orca-2 高达 16.0 倍,Gemma 高达 19.8 倍(有关每个模型的更多详细信息,请参阅下方链接的博客)。由于特殊的 GemV 内核实现,采用 int4 量化的 ONNX Runtime 在批处理大小为 1 时表现最佳。总体而言,ONNX Runtime 在多种批处理大小和提示长度下都表现出显著的性能提升。
ONNX Runtime 在训练大型语言模型(LLM)方面也显示出显著优势,这些优势通常会随着批处理大小的增加而增大。例如,在 2 块 A100 GPU 上,对于使用 LoRA 的 Phi-2 模型,ORT 比 PyTorch Eager 模式快 1.2 倍,比 torch.compile 快 1.5 倍。ORT 对于其他大型语言模型(如 Llama、Mistral 和 Orca-2)结合 LoRA 或 QLoRA 也显示出优势。
要了解更多关于如何使用 ONNX Runtime 1.17 提高生成式 AI 模型性能的信息,请查看我们最近在 ONNX Runtime 博客上发布的文章:使用 ONNX Runtime 加速 Phi-2、CodeLlama、Gemma 及其他生成式 AI 模型。
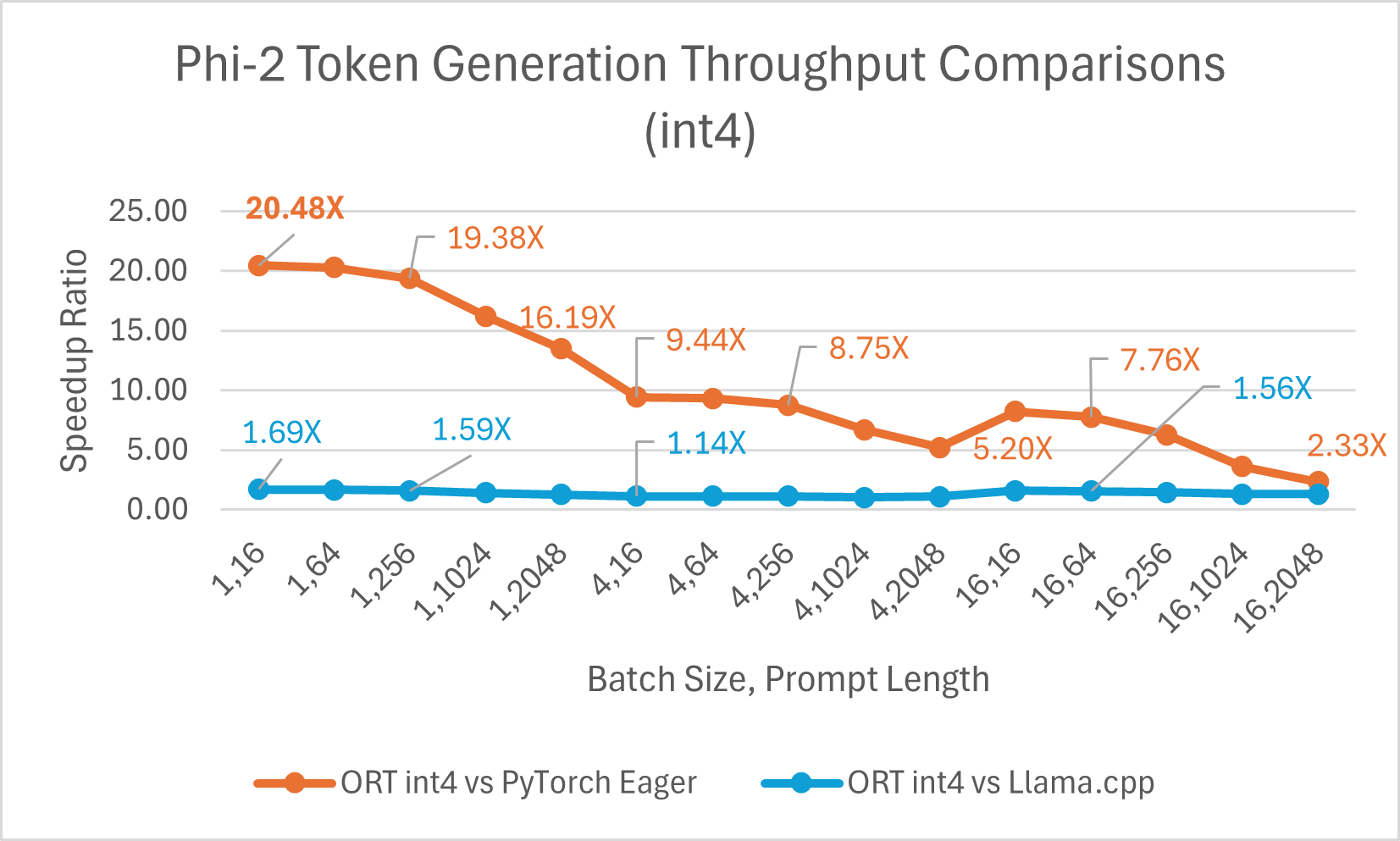
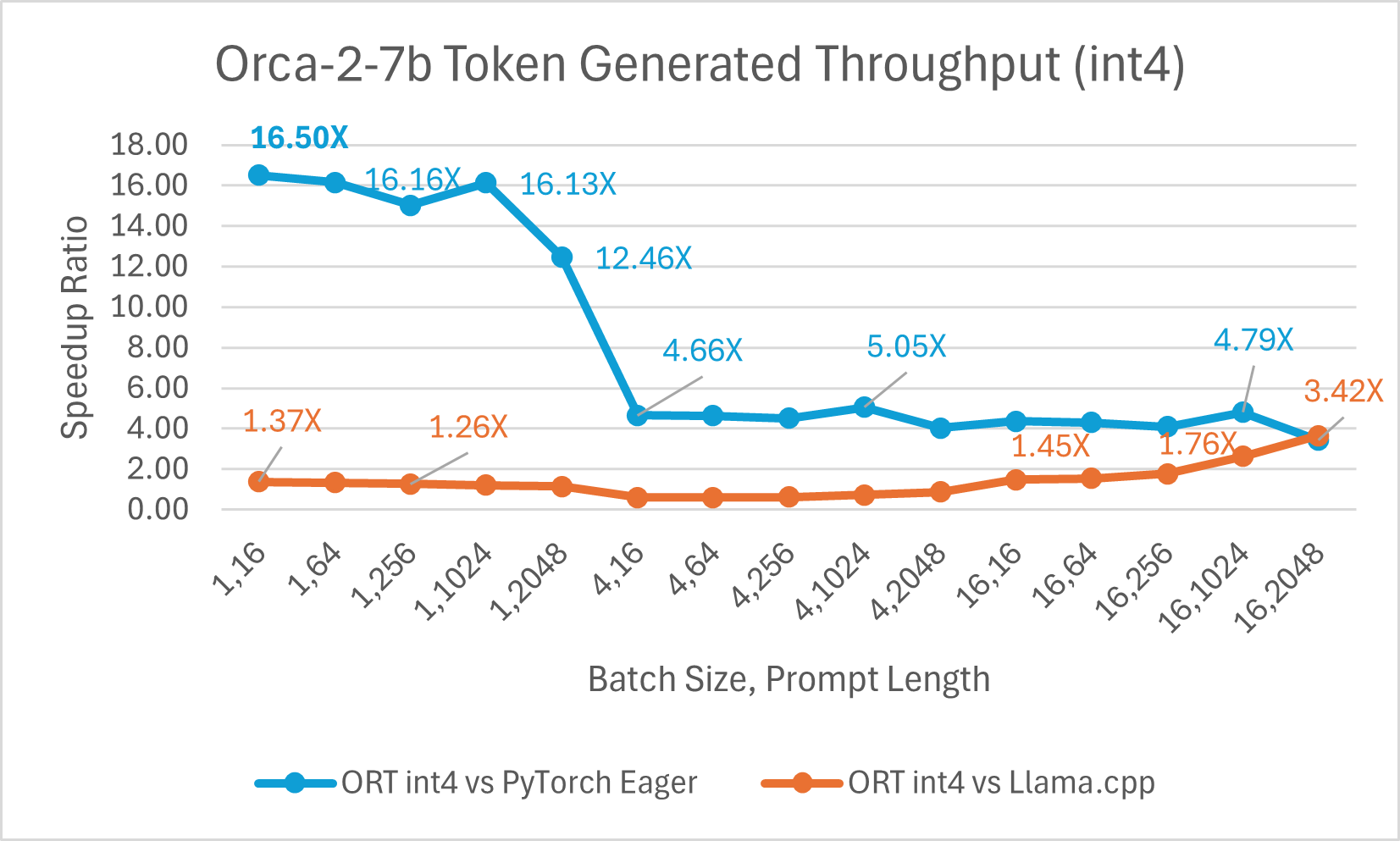
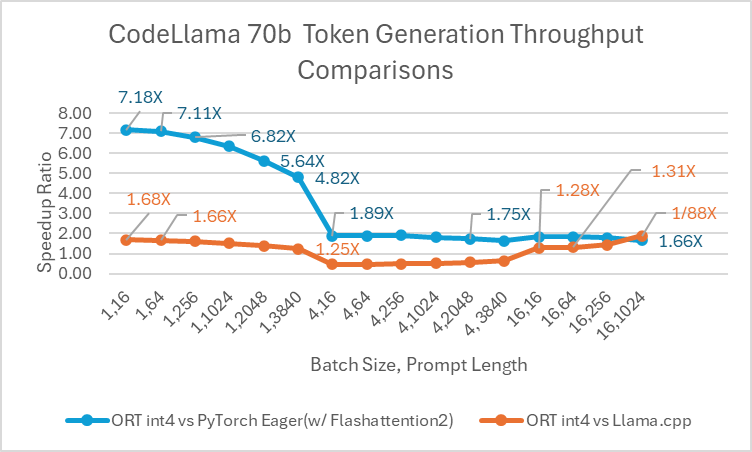
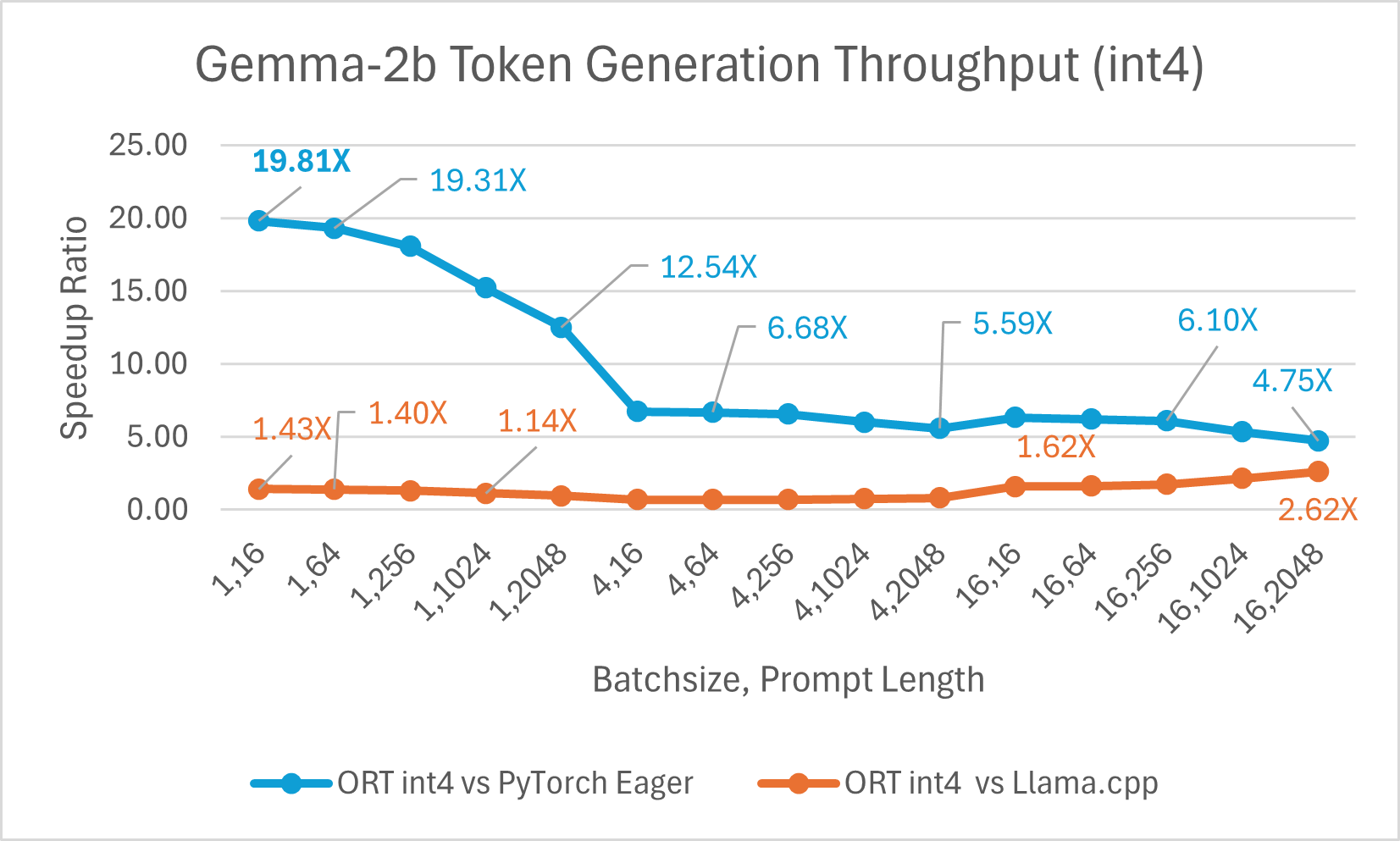
浏览器内训练
设备端训练允许您使用设备数据来改善开发人员应用程序的用户体验。它支持联邦学习等场景,即使用设备上的数据训练全局模型。通过 1.17 版本,ORT 现在将支持在浏览器中使用设备端训练来训练机器学习模型。
要了解更多关于如何通过设备端训练在浏览器中训练模型的信息,请查看微软开源博客上的这篇最新文章:设备端训练:在浏览器中训练模型。

DirectML NPU 支持
随着 DirectML 1.13.1 和 ONNX Runtime 1.17 的发布,DirectML(Windows 机器学习平台 API)现已提供神经网络处理器(NPU)加速的开发者预览支持。此开发者预览版本支持在配备英特尔® 酷睿™ Ultra 处理器和英特尔® AI 加速技术的新款 Windows 11 设备上运行部分模型。
要了解更多关于 DirectML 中 NPU 支持的信息,请查看 Windows 开发者博客上的这篇最新文章:DirectML 中引入神经网络处理器(NPU)支持(开发者预览版)。
ONNX Runtime Web 与 WebGPU
WebGPU 使 Web 开发者能够利用 GPU 硬件进行高性能计算。ONNX Runtime 1.17 版本正式推出了 ONNX Runtime Web 中的 WebGPU 执行提供程序,这使得复杂的模型能够在浏览器中完全高效地运行(查看 WebGPU 浏览器兼容性列表)。这项进步通过 SD-Turbo 等模型的有效执行得到了证明,为基于 CPU 的浏览器内机器学习难以达到性能标准的场景开辟了新的可能性。
要了解更多关于 ONNX Runtime Web 如何通过 WebGPU 进一步加速浏览器内机器学习的信息,请查看我们最近在微软开源博客上发布的文章:ONNX Runtime Web 利用 WebGPU 在浏览器中释放生成式 AI 的力量。
ONNX Runtime Mobile 中的 YOLOv8 姿态估计场景
此版本新增了对运行 YOLOv8 模型进行姿态估计的支持。姿态估计涉及处理图像中检测到的对象,并识别图像中人物的位置和方向。核心 YOLOv8 模型返回一组关键点,代表被检测人物身体的特定部位,例如关节和其他显著特征。将预处理和后处理包含在 ONNX 模型中,使得开发人员可以直接提供输入图像(可以是常见图像格式或原始 RGB 值),并输出带有边界框和关键点的图像。
要了解更多关于如何在移动设备上构建和运行包含内置预处理和后处理的 ONNX 模型以进行对象检测和姿态估计的信息,请查看 ONNX Runtime 文档中我们最近的教程:使用 YOLOv8 进行对象检测和姿态估计。

CUDA 12 软件包
作为 1.17 版本的一部分,ONNX Runtime 现在通过引入适用于 Python 和 NuGet 的 CUDA 12 软件包,确保了与 Nvidia CUDA 执行提供程序的多个版本兼容。通过这种更灵活的方法,用户现在可以同时使用 CUDA 11 和 CUDA 12,从而更无缝地集成尖端硬件加速技术。
要为 ONNX Runtime GPU 安装 CUDA 12,请参阅 ONNX Runtime 文档中的说明:安装 ONNX Runtime GPU (CUDA 12.X)。