如何使用 ONNX Runtime 开发移动应用程序
ONNX Runtime 为您提供了多种选项,可以将机器学习添加到您的移动应用程序中。本页面概述了开发流程。您也可以查看本节中的教程
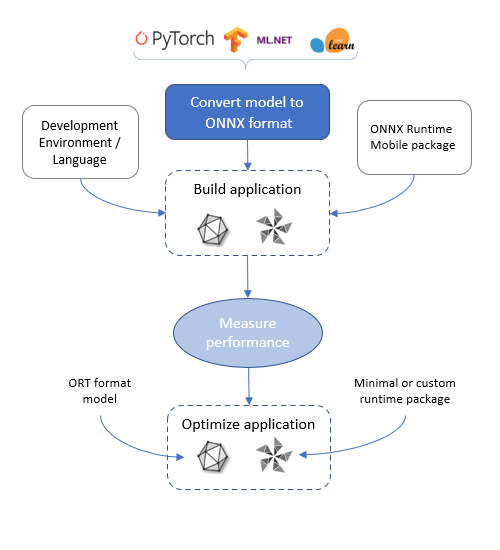
ONNX Runtime 移动应用程序开发流程
获取模型
开发您的移动机器学习应用程序的第一步是获取模型。
您需要了解您的移动应用程序场景,并获取一个适合该场景的 ONNX 模型。例如,应用程序是分类图像、在视频流中进行目标检测、总结或预测文本,还是进行数值预测。
要在 ONNX Runtime 移动版上运行,模型需要采用 ONNX 格式。ONNX 模型可以从 ONNX 模型库获取。如果您的模型尚未采用 ONNX 格式,您可以使用其中一个转换器将其从 PyTorch、TensorFlow 和其他格式转换为 ONNX。
由于模型是在设备上加载和运行的,因此模型必须适应设备磁盘并能够加载到设备的内存中。
开发应用程序
一旦有了模型,您就可以使用 ONNX Runtime API 加载并运行它。
您使用的语言绑定和运行时包取决于您选择的开发环境和您正在开发的目标。
- Android Java/C/C++: onnxruntime-android 包
- iOS C/C++: onnxruntime-c 包
- iOS Objective-C: onnxruntime-objc 包
- MAUI/Xamarin 中的 Android 和 iOS C#: Microsoft.ML.OnnxRuntime 和 Microsoft.ML.OnnxRuntime.Managed
有关包的具体说明,请参阅安装指南。
上述所有包都包含完整的 ONNX Runtime 功能和操作符集,并支持 ONNX 格式。我们建议您从这些包开始开发您的应用程序。可能需要进一步优化,详细信息如下。
根据目标平台,您可以在应用程序中选择使用不同的硬件加速器
- 所有目标都支持 CPU,这是默认设置
- 在 Android 上运行的应用程序还支持 NNAPI 和 XNNPACK
- 在 iOS 上运行的应用程序还支持 CoreML 和 XNNPACK
加速器在 ONNX Runtime 中称为执行提供程序(Execution Providers)。
如果模型是量化模型,请从 CPU 执行提供程序开始。如果模型未量化,请从 XNNPACK 开始。这些是最简单、最一致的,因为所有内容都在 CPU 上运行。
如果 CPU/XNNPACK 不满足应用程序的性能要求,请尝试 NNAPI/CoreML。这些执行提供程序的性能取决于设备和模型。如果模型由于使用了执行提供程序不支持的操作符(例如,由于较旧的 NNAPI 版本)而被拆分为多个分区,则性能可能会下降。
在创建 ONNXRuntime 会话并加载模型时,会在 SessionOptions 中配置特定的执行提供程序。有关更多详细信息,请参阅您的语言API 文档。
测量应用程序性能
根据目标平台的要求测量应用程序的性能。这包括
- 应用程序二进制大小
- 模型大小
- 应用程序延迟
- 功耗
如果应用程序不符合其要求,可以应用优化。
优化您的应用程序
减小模型大小
减小模型大小的一种方法是量化模型。这会将一个原始的 32 位权重的模型缩小约 4 倍,因为权重被减小到 8 位。有关操作说明,请参阅 ONNX Runtime 量化指南。
另一种减小模型大小的方法是找到一个具有相同输入、输出和架构,并且已经针对移动设备进行优化的新模型。例如:MobileNet 和 MobileBert。
减小应用程序二进制大小
为了减小 ONNX Runtime 二进制文件的大小,您可以根据您的模型构建一个自定义运行时。
请参阅构建自定义运行时的过程。
ORT 格式转换的输出之一是构建配置文件,其中包含模型的操作符列表及其类型。您可以将此配置文件作为输入用于自定义运行时二进制构建。
为了让您了解预构建包和自定义构建之间的二进制大小差异
| 文件 | 1.18.0 预构建包大小 (字节) | 1.18.0 自定义构建大小 (字节) |
|---|---|---|
| AAR | 24415212 | 7532309 |
jni/arm64-v8a/libonnxruntime.so,未压缩 | 16276832 | 3962832 |
jni/x86_64/libonnxruntime.so,未压缩 | 18222208 | 4240864 |
此自定义构建支持运行 ResNet50 模型所需的操作符。它要求使用 ORT 格式模型(因为它使用 --minimal_build=extended 构建)。它支持 NNAPI 和 XNNPACK 执行提供程序。